
Fog computing extends cloud services to edge devices. This concept was developed to address the latency issues associated with centralized cloud computing systems. Due to the rapid expansion of both commercial and consumer devices connected to the internet, cloud resources are under extreme pressure.
But how does fog computing work? And what does its architecture look like? We’ll cover these topics and more in this article, such as essential characteristics and challenges, including:
Read our guide below on edge computing for more information:
 AIAI
AIAI
What is fog computing?
Also known as fog networking or fogging, fog computing refers to a decentralized computing infrastructure, which places storage and processing at the edge of the cloud.
The word ‘fog’ relates to the cloud-like properties in the architecture, with devices generating large volumes of raw data. Instead of sending all of this data to the cloud for processing, fog computing does as much processing as it can by using computing units within the data-generated devices.
This means that processed data (not raw data) is forwarded, reducing bandwidth requirements.
Fog computing architecture
There are three main hierarchies in the fog computing architecture:
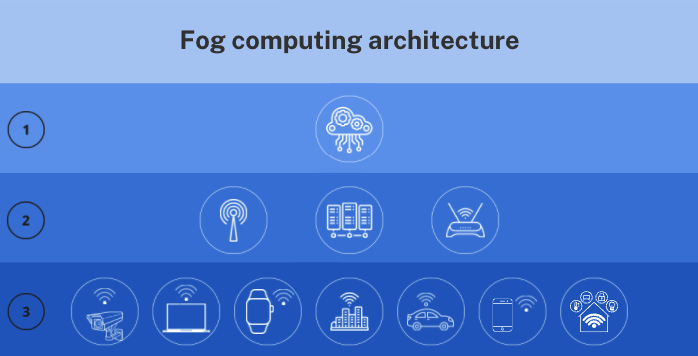
1) Cloud
Cloud consists of devices that can offer large storage and high-performance servers. The cloud stores data and performs computation analysis permanently for both permanent access and backup for users.
It has powerful computing capabilities and high storage capacity, typically formed by large data centers that offer users cloud computing’s basic characteristics. The cloud is at the extreme end of the architecture and stores data that isn’t needed at user proximity level.
2) Fog
The fog is comprised of devices such as access points, routers, fog nodes, and more. Fog nodes live at the edge of a network, in-between end devices, and cloud data centers.
These nodes can be static (e.g. in bus terminals) or moving (e.g. inside smart vehicles), guaranteeing services to end devices and being able to temporarily compute, transfer, and store data.
Connections between fog nodes and cloud data centers are possible thanks to the IP core networks, which offer cooperation and interaction with the cloud for enhanced storage and processing.
3) Edge
This is the basic level in the architecture, including devices such as smart vehicles, mobile phones, sensors, and more. The edge contains devices that can sense and capture data. These devices are distributed over various locations far away from each other.
Mainly dealing with data sensing and capturing, devices can work in a heterogeneous environment with devices from other technologies and communication modes.
The 6 layers of fog computing
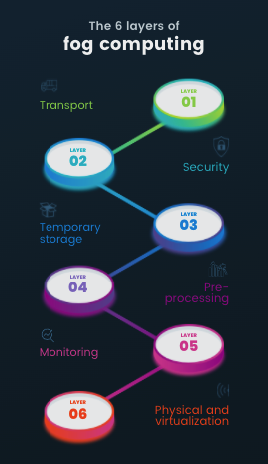
1. Transport layer
With the primary function being to upload partly-processed and fine-grained data to the cloud for permanent storage, the transport layer passes data through smart-gateways before it uploads it onto the cloud. Because of the limited resources of fog computing, it uses lightweight and efficient communication protocols.
2. Security layer
Dealing with data privacy, data encryption and decryption, and data integrity, this layer makes sure that privacy is secure and preserved for data that is outsourced to the fog nodes. When it comes to fog computing, privacy can be data-based, use-based, and location-based.
3. Temporary storage layer
Associated with the replication and non-permanent distribution of data, data is removed from this layer from the temporary layer when moved to the cloud. Storage virtualization like VSAN is used.
4. Pre-processing layer
Several data operations, mostly connected to analysis, are performed by the pre-processing layer. It cleans data and checks it for unwanted data, with impurities being removed and only useful data collected. Data analysis conducted can be related to relevant and meaningful information mining from end device-collected data.
5. Monitoring layer
This layer undertakes node monitoring, such as the amount of time they work, maximum battery life of device, temperature, and more. The nodes are also checked for how much energy they consume while performing tasks, and application performance is also monitored.
6. Physical and virtualization layer
Including both virtual and physical nodes, these conduct data capturing as a primary task. Sensing technology captures the nodes’ surrounding and collects data to send to the upper layers through gateways to allow for further processing.
Essential characteristics of fog computing
Mobility
With various fog computing applications communicating with mobile devices, these applications are conducive to mobility techniques like Locator/ID Separation Protocol (LISP). LISP’s main task is to decouple the identity and location.
Low latency
End devices have quicker generation and analysis of data thanks to the fog nodes’ connectivity with smart and efficient end devices, resulting in lower data latency.
Scalability and agility
Fog-node clusters are adaptive at the cluster level, which allows them to support the majority of functions. These can be network variations, elastic computers, and data-load changes.
Heterogeneity
As a heterogeneous infrastructure, fog computing collects data from various sources. This virtualized platform offers end-user storage and other services such as networking. This means it acts like a bridge between traditional cloud computing centers and end devices.
Real-time interactions
Vital fog computing applications deal with real-time interactions instead of conducting batch processing.
Geographical distribution
Unlike the more centralized cloud, fog computing’s services and applications have widely distributed deployments.

Challenges of fog computing
There are a few challenges to keep in mind to make sure the fog runs smoothly.
Management
With the large number of small devices that need to be configured, the fog needs a decentralized and scalable management mechanism.
Programmability
Application lifecycle is a challenge that the cloud is already facing, as the presence of droplets (small functioning units) in more devices requires the right abstractions in place, to make sure programmers don’t deal with these issues.
Discovery/sync
A centralized point may be needed for applications that run on devices. This can be important to establish an upstream backup, especially when there are too few peers in storage applications.
Security
Fog device hosting applications can also expect to have the same concerns as current virtualized environments. Trust and privacy are issues to consider, as the fog processes user data in third-party software and hardware.
Standardization
Fog computing needs standardized mechanisms to make sure every area of the network can both announce availability to host other components of software and for others to send their own software to be run.
Compute/storage limitation
Even though modern devices are improving, fog computing stills needs more efficient and powerful devices to tackle its requirements.
How does fog computing work?
Fog computing uses local devices (fog nodes or edge devices), which are located closer to data sources and have higher storage and processing capabilities. These nodes can process data much faster than sending a request to the could for centralized processing.
IoT (Internet of Things) beacons capture raw data, which is sent to a fog node close to the data source, and the data is locally analyzed and filtered before being sent to the cloud for long-term storage. Edge devices include:
- Switches
- Cameras
- Routers
- Controllers
- Embedded servers
However, any device that has storage, computing, and network connectivity can also act as a fog node. When there’s a large and distributed network, these nodes are placed in various key areas to allow for essential information to be analyzed and accessed locally.
Fog computing process:
- Signals are transmitted from IoT devices to automation controllers that execute a control system program. The devices are then automated.
- The control system program transmits the data through protocol gateways.
- The data is converted into protocols like HTTP, making sure it can easily be understood by internet-based services.
- Fog nodes collect the data for a more comprehensive analysis.
- Data is filtered and saved for use at a later date.

Fog computing vs edge computing
When it comes to edge computing vs fog computing, it’s important to note that the cloud is getting cluttered with the number of devices that now connect to the internet. And because cloud computing isn’t ideal for all cases, it’s now become necessary to use fog computing for IoT devices.
Edge computing is a component of fog computing, referring to data being analyzed at the point of creation, or locally. Fog computing comprises edge processing and network connections needed to bring data from the point of creation (the edge) to its endpoint.
Fog-empowered devices can analyze time-critical data locally, like device status, alarm status, fault warnings, and more, to minimize latency and prevent damage. The amount of bandwidth needed is also minimized, which speeds up communication with the cloud and sensors.
Fog computing examples
Smart homes
Smart homes have technology-controlled heating and ventilation, smart intercom systems, smart lighting, and more. Fog computing can create personalized alarm systems and automate events like turning on sprinklers at a set time.
Video surveillance
Continuous video streams are large and difficult to transfer across networks, making them ideal for fog computing. This large data can cause network and latency issues - often even including high costs for media content storage.
Fog nodes can detect problems in crowd patterns from video surveillance used in public spaces, and even alert authorities if needed.
Smart cities
Fog computing can be a huge asset when it comes to traffic management, as sensors are placed at road barriers and traffic signals to detect pedestrians, vehicles, and cyclists. The sensors use cellular and wireless technologies to collate data and transmit to traffic signals, which then turn red automatically or stay green for longer according to processed data.
Healthcare
The healthcare sector benefits from real-time data analysis, such as information from blood glucose monitors and vital drops from wearables. As this data can’t have latency issues due to its critical nature, fog computing is an important factor.



AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

