
With modern advancements in artificial intelligence and computational power, computer vision has become an integral part of everyday life. Computers’ ability to ‘see’ and interpret the world around them helps in the analysis of the massive amounts of data created in daily operations.
Modern computer vision uses machine learning algorithms, more specifically a neural network, to determine insights from this data. These neural networks extract patterns from samples, working similarly to human brains.
In this guide, we’ll cover:
- What is computer vision?
- How does computer vision work?
- A brief history of computer vision
- Computer vision applications
What is computer vision (Vision AI)?
Computer vision, or Vision AI, is a field of computer science that aims to create digital systems that are able to process, analyze, and use visual data in the way that a human will do. It derives important information from digital images or other visual inputs, and then takes actions or makes recommendations based on the information it gets.
Artificial intelligence lets computers think, and computer vision lets them see by training machines to undertake specific tasks.
The core principle of Vision AI is centered on machines and computing devices making intelligent decisions after the interpretation of visual data. Vision AI applications can be further broken down into branches like:
- Object classification
- Object detection
- Object tracking
- OCR (optical character recognition)
Object Classification
With Vision AI, a camera can classify by looking at a picture whether it depicts a dog or a cat. This category of Vision AI is called object classification, and the deep learning models used for it are referred to as classification models.

Classifying images is the process of organizing them into categories on the basis of their features or characteristics. Classification is the process of identifying which classes (objects) are present in the visual data. It’s useful on a yes/no level for finding out whether an image contains an object/anomaly or not.
Object Detection
Object detection is a technology that uses machine vision to understand, identify, and detect different objects in a particular area/frame. Example: cars on a road, lampposts on a sidewalk.

Widely used in factories with object detection, manufacturers can detect the presence of unwanted objects on their factories' belts. It’s also quite prominent amongst food manufacturers who use this solution to identify and filter out unwanted debris, human hair, and micromachine parts, and protect their food products from contamination.
Object Tracking
Object tracking is all about the movement or motion of a targeted object within a frame. It can be used to monitor the movements of customers in a shop or the speed of moving vehicles.
used for many things, such as sports analytics or a factory environment, to ensure all workers wear safety gear. You can also program pose-based tracking to focus specifically on particular body parts of a person.
With the help of object tracking, cameras can identify objects in a video and interpret them as a set of trajectories with high accuracy. Objects in the video are tracked frame by frame. People tracking is one of the biggest applications of this solution with widespread applications in almost every industry.
Optical Character Recognition
Can a camera look at a text and be able to read it? That's how simple it was when it started. We slowly progressed from being able to read a single line to being able to read an entire paragraph. Now we can convert non-linear texts, diagrams, and tables into digital formats and machine-readable data.
OCR can capture data from different sections of a document, segregate it, and organize it accordingly into a sanitized digital format.

If we consider the example of a passport, OCR scanning can extract information from every column like the name, address, last issued date, etc., and arrange it accordingly in a digital format. The biggest everyday use of this Vision AI application can be witnessed at banks that use this OCR to process cheques and passbooks.
How does computer vision work in practice?
1. Image acquisition
Through real-time photos, video, or 3D technology, images are acquired in both small and large sets.
2. Image processing
Image processing is a mostly automated process due to deep learning models, which need to first be trained by being fed tens of thousands of pre-identified or labeled images.
3. Image understanding
Objects are classified or identified.
Even though computer vision can be summarized in three simple steps, image processing and understanding can be challenging. A single image is composed of many pixels, or picture elements, which is the smallest quanta - the plural of quantum, representing the minimum amount of any physical object in an interaction - in which we can divide an image into.
Computers then process images in an array of pixels, with each pixel having a set of values that represent both the intensity and the presence of the primary colors: Red, Green, and Blue. The RGB color model is often used in color images, with each pixel being a mix of these three colors.
As computers can only understand numbers, each pixel is then represented by three numbers, which correspond to the amount of red, green, and blue in each pixel. With grayscale images, each pixel is just one number, representing the intensity or amount of light it has. This scale is often represented from 0 (black) to 255 (white), with everything in between being various shades of gray.
The array of pixels forms a digital image, which becomes a matrix. Complex applications will have operations such as downsampling via pooling and convolutions with learnable kernels, while simpler algorithms make use of linear algebra to manipulate a matrix.
Computers have to use algorithms that can recognize complex patterns in images by performing complex calculations on the matrices to extrapolate relationships between pixels.
Three operations that are based on deep learning perspectives and often utilized in computer vision are:
- Convolution. An operation in which a learnable kernel is ‘convolved’ with an image, meaning that the kernel is slides pixel by pixel across an image. An element-wise multiplication is then made between both image and kernel at every pixel group.
- Pooling. The dimensions of an image are reduced by undertaking operations at a pixel level. The way it works, a kernel slides across an image, with only one pixel from a corresponding pixel group being chosen for more processing, which reduces the size of the image.
- Non-linear activations. The stacking of multiple convolutions and pooling blocks increases model depth due to the introduction of non-linearity in the neural network.
A brief history of computer vision
1959: Computer vision experimentation starts, with neurophysiologists showing an array of images to a cat and trying to correlate a response in the brain. They found that the cat first responded to hard lines, which meant that image processing begins with simple shapes. The first computer image scanning technology was developed around the same time, which let computers both digitize and acquire images.
1963: Computers are able to transform 2D images into 3D forms. The 1960s were marked by the emergence of AI as an academic field of study, alongside being the beginning of AI trying to solve human vision problems.
1974: The introduction of optical character recognition (OCR) technology. It was able to recognize printed text in any typeface or font. Intelligent character recognition (ICR) could decode hand-written text through neural networks. Both OCR and ICR have since been applied to mobile payments, vehicle plate recognition, and more.
1982: Neuroscientist David Marr determines that vision is hierarchical, and introduces machine algorithms to detect corners, edges, curves, and other basic shapes. Computer scientist Kunihiko Fukushima develops a network of cells that is able to recognize patterns, called Neocognitron, which has convolutional layers in a neural network.
2000s: In 2001, the first real-time face recognition applications begin to appear. Object recognition becomes the focus throughout the decade, alongside the emergence of the standardization of how visual data sets are both tagged and annotated.
2010: The ImageNet data set is available, containing millions of tagged images over a thousand object classes. It provides the foundation for CNNs (Convolutional Neural Networks) and deep learning models.
2012: A CNN is entered into an image content by a team from the University of Toronto. The mode, AlexNet, majorly reduces error rates for image recognition to only a few percent.
What are the main applications of computer vision?
Object detection
Using bounding boxes, it detects and locates objects by looking for class-specific details in a video or image. It then identifies them whenever the details appear. These classes are divided into what the detection model has been trained to classify, like animals. Object detection methods previously used HOG Features, Haar Features, and SIFT based on classical machine learning approaches.
Face recognition
A subpart of object detection, face recognition’s primary object to detect is the human face. As an application, it’s similar to object detection, but it also undertakes object recognition. These systems look for landmarks and common features, such as lips or eyes, to classify a face by using features and landmark positioning.
Scene reconstruction
An extremely complex application, scene reconstruction relates to the 3D reconstruction of objects from photos. Algorithms usually reconstruct objects through the formation of point clouds on object surfaces and then reconstruct a mesh from the point cloud.
Video motion analysis
Studying moving animals or objects and their trajectories, it combines tracking, object detection, pose estimation, and segmentation. It can be used in areas like manufacturing, medicine, sports, and more.
Image classification
Probably the most popular application in computer vision, it classifies a group of images into a set of predefined classes by only using a set of sample images that are already classified. It deals with the processing of entire images and assigns specific labels to them.
Image restoration
Image restoration is the restoration or reconstruction of old or faded hard copies of images that have lost their quality. This process usually involves reducing additive noise through mathematical tools or image inpainting, if further analysis is needed.
With image inpainting, generative models make an estimate of what the damaged parts of images mean to fill them in. Should images be in black and white, a colorization process usually follows in a realistic way.
Edge detection
Using mathematical methods that aid in the detection of sharp changes or discontinuities in image brightness, it detects boundaries in an object. Edge detection is usually utilized as a pre-processing step in many applications, mainly being done through convolutions that have specially-designed edge detection filters and through traditional image processing-based algorithms such as Canny Edge.
Edges in images provide valuable information about the images’ contents, meaning that deep learning methods perform edge detection internally to capture global low-level features through learnable kernels.
Want to learn about edge computing? Read more in our guide below:
 AIAI
AIAI
Image segmentation
Image segmentation relates to the division of an image into sub-objects or subparts to show that the machine can distinguish an object from either the background or another object in the image. An image ‘segment’ represents a certain class of object that has been identified in an image by the neural network and is then represented by a pixel mask that can be utilized to extract it.
Both modern deep learning architectures (like FPN, SegNet, etc) and traditional image processing algorithms have been used to study image segmentation.
Feature matching
Features are regions in images that provide the most information about specific objects in the images. Edges and corners can be big indicators of object details, making them vital features. This helps to make correlations of features in similar regions of a particular image with regions of another image. Feature matching is typically used for camera calibration and object identification, and tends to be performed in the following order:
- Feature detection. Regions of interest are detected by image processing algorithms like SIFT.
- Formation of local descriptors. When features are detected, regions that surround keypoints are captured and local descriptors obtained. These are the representations of a point’s local neighborhood.
- Feature matching. Local descriptors and features are matched in corresponding images.
Medicine
Image segmentation can be effective during the analysis of medical scans, by detecting disease and rating its severity. With image information being around 90% of all medical data, computer vision is an important process in diagnosis.
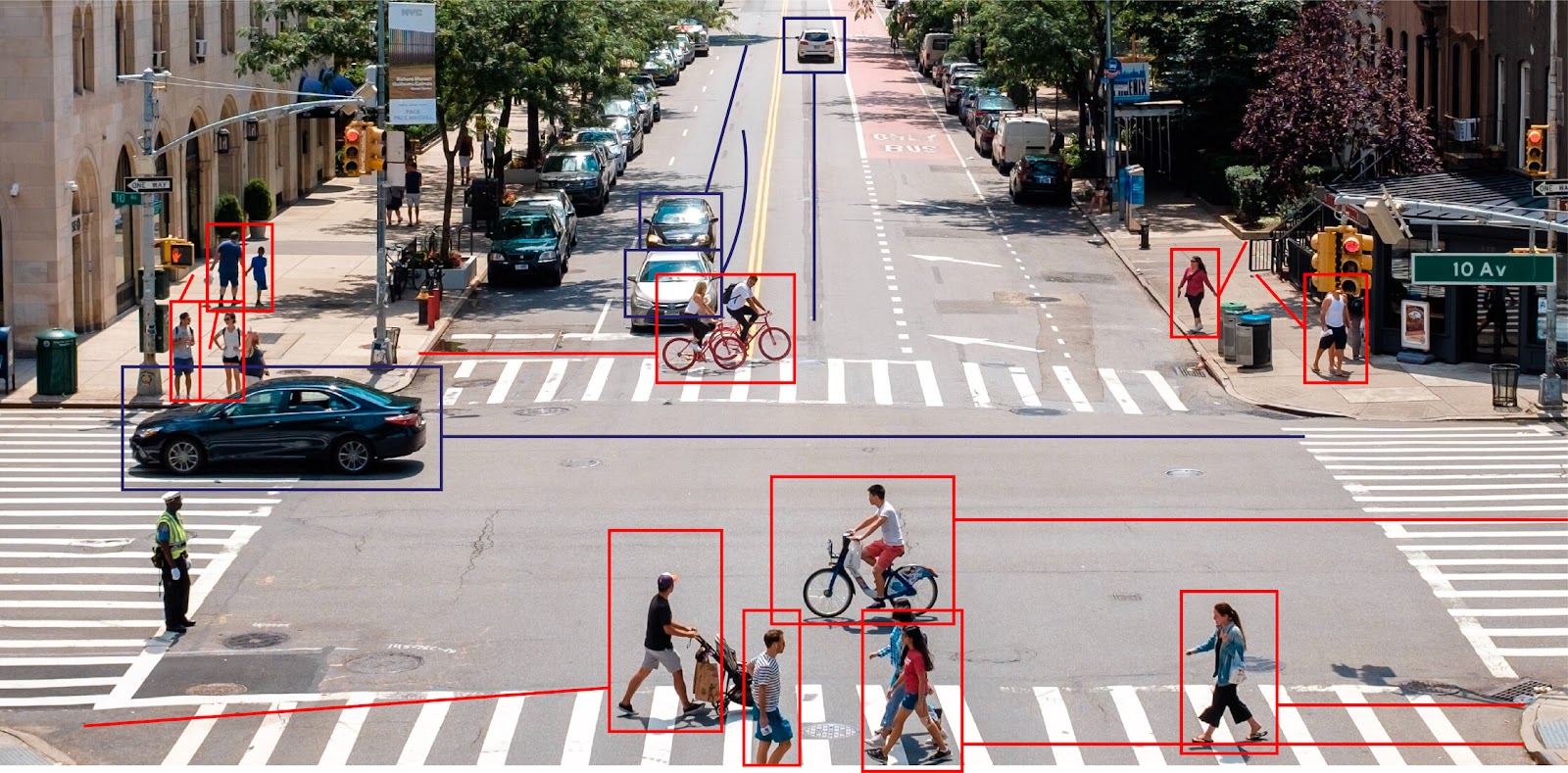
Self-driving cars
Smart vehicles use their cameras to capture videos from several angles, sending these videos an input signal to computer vision software. The video is then processed in real-time to detect objects such as traffic lights and pedestrians.
Augmented reality
Computer vision helps augmented reality apps in the detection of physical objects, like individual objects and surfaces, in real-time to place virtual objects in the physical environment.
Content organization
Apple Photos, for example, automatically tags photos and lets users browse structured photograph collections, alongside creating curated views of users’ best moments.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

