
Jean-Guillaume Durand, Head of Perception at Xwing, gave this presentation at the Computer Vision Summit in San Jose in 2023.
We've seen a few great applications of AI so far. But the question I want to raise is, what happens when you try to put these systems on commercial aircraft?
This is what we're going to talk about today.
Journeying into autonomous aviation with Xwing
My background is mostly in aerospace engineering studies, starting in France. Then I finished my doctorate at Georgia Tech in Atlanta.
At the same time, it turned out that Amazon was starting their drone delivery program in Seattle, so I joined them as one of their first interns in 2015.
Then I moved on to larger platforms with commercial aircraft with Airbus. And as of last year, I've been leading the perception effort at Xwing, which focuses more on cargo aircraft of smaller sizes.
The work I'm presenting here is a collaboration with the Stanford Center for AI Safety (SAFE), and it's also a succession of papers that we've published or are going to have published.
We're going to focus mainly on runway detection as an application, and how we think about certifying AI systems for this application at Xwing.
But first, let me talk a little bit about my company and what we do.
We retrofit existing aircraft with autonomous technology to be able to automate the cargo market. We believe that by focusing first on smaller platforms or on just cargo instead of passengers, we're able to have a much bigger impact and also learn from the experience, as opposed to moving directly to passenger aircraft.
We operate a few routes in the US with all 35 aircraft. All those flights happen with UPS, and there are around 400 flights per week. And those aircraft are piloted by human pilots.
This is in parallel to the autonomous part of the business that we have, and we're going to talk about that as well.
In 2021, we expanded the first fully autonomous flight gate-to-gate with a cargo aircraft without any human intervention.
For the R&D part of the business, the image below is the aircraft that we retrofit with what we call sensor pods. We’re currently in the process of certifying those, and they're here for data collection. But we also have control over the actuators of the aircraft.

So far, with this technology that we call SuperPilot, we've done more than 200 fully autonomous flights, and we've accumulated a lot of flight hours on that platform. Fun fact, the longest flight was around 800 miles, and I believe it was a fully autonomous mission to deliver masks during the COVID crisis.
Machine learning for autonomous flight
So, where do we apply machine learning at Xwing in this autonomous flight domain?
You first start by breaking the flight down into the different phases. You might be interested before you even turn on the engine to see if the propeller is clear of any obstacles.
Then you taxi to the runway. While you taxi, you might be interested in detecting whether there are any obstacles around the vehicle.
During take-off, again, you make sure that the runway is clear of any obstacles. You try to follow the center line so you can do a little bit of navigation with the sensors.
And then comes the critical part of landing. Landing is the process of guiding the aircraft to the runway, and you can do that with machine learning and computer vision as well.
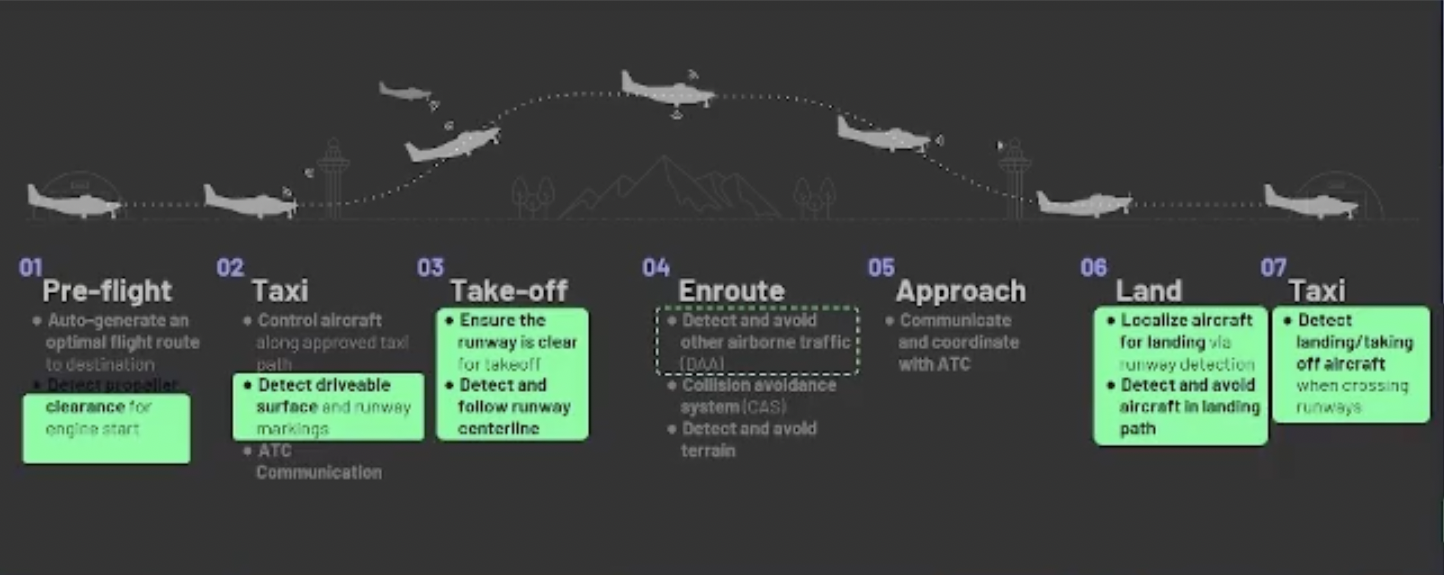
There's a bunch of cool applications that you could do with machine learning for autonomous flight and computer vision.
Detect-and-avoid can be done on the ground. Imagine that we're about to enter the runway, but there's another aircraft already landing on that runway. Having those sanity checks in place really helps to maintain safety during your operations.
You can also do detect-and-avoid in the air too to make sure you don't come too close to any other airborne traffic.
You can use computer vision to aid navigation and complement the GPS sensor that you already have to land the aircraft, or if your GPS breaks down.
There's also what I call ‘off-aircraft operations’ as well. You might be helping the crew clean the aircraft, do maintenance, set up the sensors, or do the calibration of the sensors. So you can use computer vision and AI tools to guide all the operations that happen around the aircraft.
That being said, we're going to focus mostly on vision-based landing and runway detection.
For example, the input to the system is going to be an image. There’s a camera feed from the aircraft, and you might see the corners of the runway very slightly overlaid in blue as they’re detected by our algorithm onboard.
At the bottom of the feed, you have the construction of the scene as we think it's happening based on those detections. So, we first detect the runway in the image, and from that, we reconstruct where we think the aircraft is with respect to that runway.
For the reconstruction, the aircraft highlighted in blue in the image below is our solution with computer vision, and the pink aircraft is the GPS and initial sensor solution. Here, we compare both, and as we get closer and closer to the runway, both solutions agree pretty nicely.

This is a good application, and it works great as prototyping and demos, but how would we go about certifying that for everyday operations and as a part of the business?
Approaching certification for autonomous flights
Firstly, what is certification? A very broad definition would be:
Ensuring that the hardware, software, and processes that you have in place follow a defined set of design, performance, and safety, and ultimately have a very low probability of failure to maintain the safety of the general public.
On one side, we could maybe consider autonomous driving. There’s one administration that takes care of all these guidelines. Currently, I believe there are a few federal guidelines in place and a lot of local state laws.
Depending on whether you operate in San Francisco or Denver, you might have different laws on what you can and can’t do with self-driving. And that applies to whether you're delivering cargo, passengers, or small packages.
On the other side, we have autonomous flight, which is administrated by the Federal Administration, or the FAA. Here, there's no clear standard policy already in place. It's very much a work in progress.
We have a few industry groups that are working on defining potential solutions to put AI on such systems, but no clear policies are out yet. This is where we step in and try to propose this type of solution here.
For autonomous driving, if you were to show a failure rate of one failure per 100 million miles, the vehicles have to drive 275 million failure-free miles. That really shows the amount of testing that you need to do just to show that safety level.
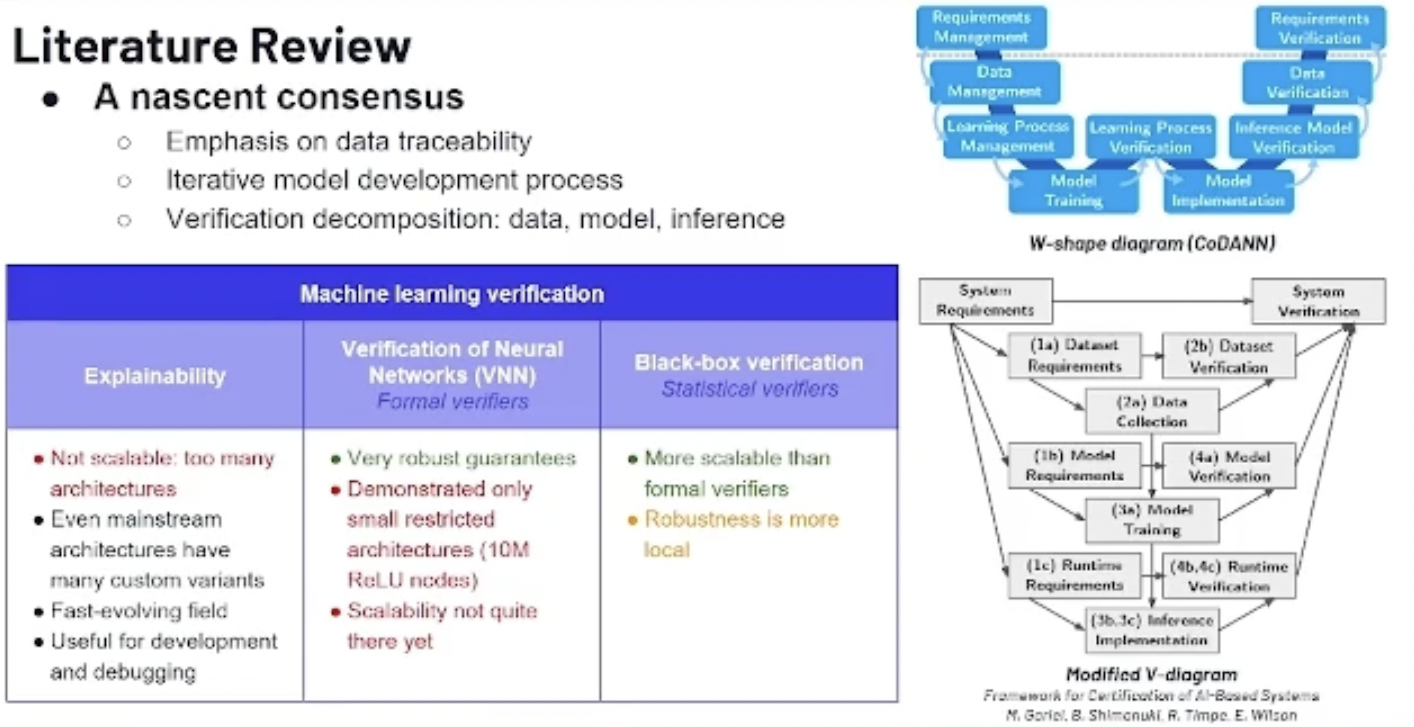
How is certification usually done in aerospace? Below are the current processes in place. It follows pretty much a traditional Engineering V diagram. As you go down the V, you decompose the system level by level and function by function. And as you go back up the V, you test each function and basically try to prove that it meets the requirements.

The problem with machine learning is that the current process sort of breaks down.
Usually, when you have software, you want to show that you have complete coverage in terms of testing, and each line of code meets a given requirement. With machine learning, however, the pioneers of your models and your software are weights. They learn from the data, and as such, they don't really correspond to any requirements.
Maybe an inspiration here would be to see how hardware is certified and how we could go about porting that to machine learning models.
Runway detection: Computing the probability of failure
For the scope of this presentation, we'll look at a notional system.
You have a mission management system and a communication system, and one of those systems is AutoFlight, which is maintaining the flight of the aircraft.
One of those sub-components would be guidance. You can do that with ILS, which is an instrumental approach that you have at most airports. You can also do that with GPS and inertial sensors. And one of the solutions that we just saw could also be done with computer vision.
For example, you might have a machine learning-based runway detector, and then a bunch of additional steps that reconstruct the runway.
The main idea and takeaway is that if you consider the stack as a whole, the machinery component on the software on the aircraft is a very small piece.
One key misconception that we often have to break down is that the AI here is not the brain of the aircraft. The output is bounded by other algorithms which are more traditional software. There are a lot of algorithms that perform very well out there and have for many years.
At Xwing, we use the machine learning component only where it can provide a clear advantage. So, in this case, this is for object detection.
For our ML component, we decompose the system, we go down the V diagram, and we assign it a function, which is to provide runway detection. That function is associated with different failure modes, and each one of them gets assigned a probability of failure.
Here, I put this notional number for the sake of the example of one failure for 100,000 approaches, and that's going to drive a requirement for this algorithm here.

In the research community, there are a few tracks and main approaches to verify the machine learning models.
The first one is explainability, where you try to dive deep into the network, the different layers, and different neurons.
However, there are many different model architectures out there, and even if you take very famous architectures, each one of those is always fine-tuned and tweaked by researchers and practitioners, so it's impossible to keep track of the different variations. That's a bit of a limitation of this approach.
For more verifiers, they provide very robust guarantees. The problem with these approaches right now is that they don’t quite scale yet to the big models that are used in the industry. More development is needed here.
What we're going to focus on is statistical verifiers.
We have this requirement of a probability of failure, and we want to find a way to compute that probability of failure for our system.
One of the ideas here is to take where we expect the aircraft to operate and decompose that into an operational domain.
On the graph below, I put the distance to the runway for the model on the x-axis, and what we call the glide slope angle on the y-axis. That defines a problem with two variables.
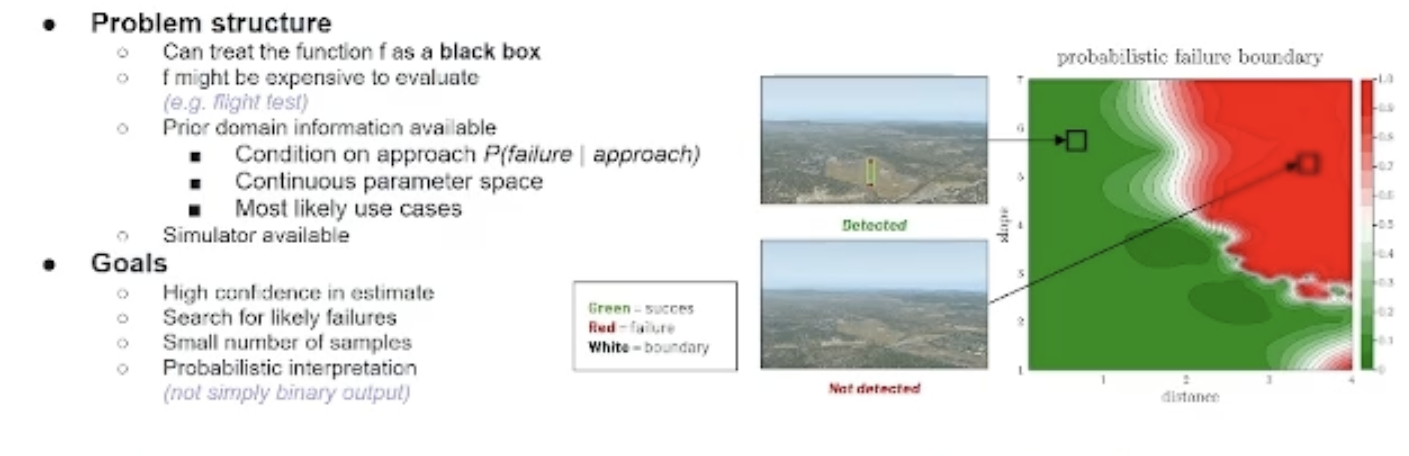
We can see in that small domain where the model fails and where it succeeds, so successes will be the green area. You can also see if we're pretty close to the runway, it’s a pretty high slope, and we detect the runway. In the red area is where we had the failures of the model, where maybe it was three nautical miles from the runway too far. We don't detect the runway.
Of course, in reality, you’ll have more than two dimensions. It's not only the distance to the runway and the glide slope angle, but maybe where you expect to operate, different airports in the world, the position of the aircraft with respect to the runway, the weather, the time of day; all these variables add up to provide the complete parametric space that we have to cover.
Here we use simulation to help us cover all those cases. We have very difficult cases in reality. For example, the sun could be in the field of view of the camera, or the aircraft is at a pretty steep angle with respect to the runway, and there’s bad weather on top of that. Simulation really helps us here.
That defines the overall parametric space we'd like to cover and compute that probability of failure over.
Sampling the parametric space
How do we sample that parametric space? A very simple idea is that we have two dimensions that we subdivide into a grid, and we evaluate the model at each of those points.
It's very intuitive and very easy to explain to the certification authorities as well. We can easily put that on a bunch of parallel machines and run it pretty quickly.
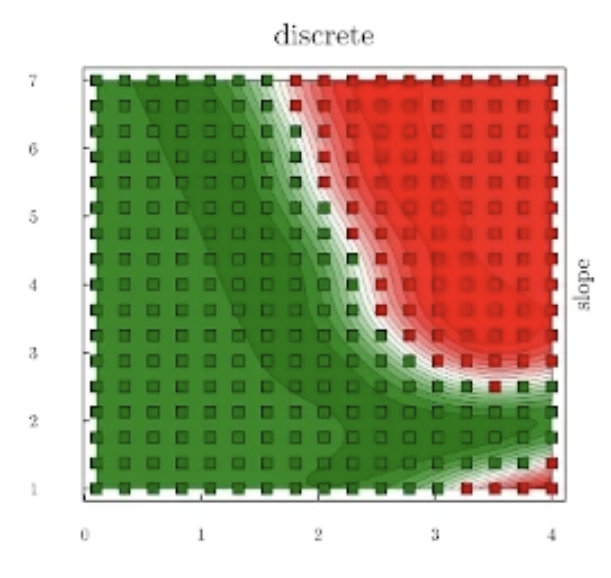
However, as you add more dimensions, there's the curse of dimensionality. You just add one more dimension to this, and all of a sudden, your number of points dramatically explodes.
The distance between your samples also becomes bigger and bigger as you add more dimensions, so there's a very high chance that in the end, between two samples, you might actually have a failure that sits there that you wouldn't discover.
How can we tweak this approach to really compute this probability of failure, this boundary failure, and try to do it in an efficient way? That's going to be our research question here.
Robert Moss and his advisor from Stanford have worked on this algorithm for probabilistic failure estimation. The main idea is that you focus on three main criteria to cover the space.
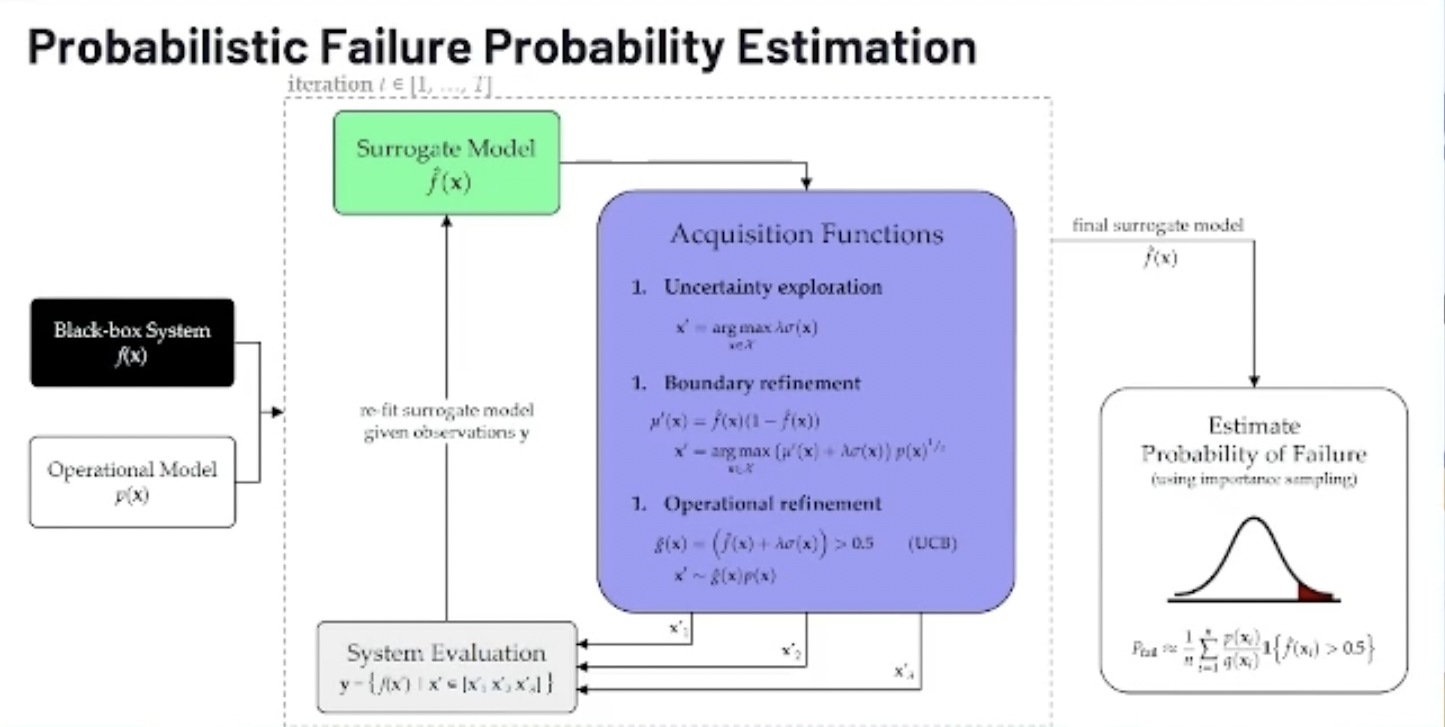
You try to add samples and points where you have a lot of uncertainty in order to reduce that uncertainty. You also try to refine where the boundary is, so when the model goes from success to failure, this is what you want to cover in detail. You try to add more samples around that region.
And the final one is operational refinement, which is most of the points you know where the model is expected to operate most of the time. For pilots, they try to do the approach mostly at a three-degree glide slope. You know that most of the points will be there and you’ll try to add more samples in that region.
Now, we're going to try to see how that works in practice.
Again, on the graph below, we have the distance of the runway on the x-axis, and the glide slope angle on the y-axis. This corresponds pretty much to the envelope here with the distance of the runway and different glide slope angles. All the points that you see here in that domain would be in that envelope here. In purple, I put the operational likelihood that we already have.
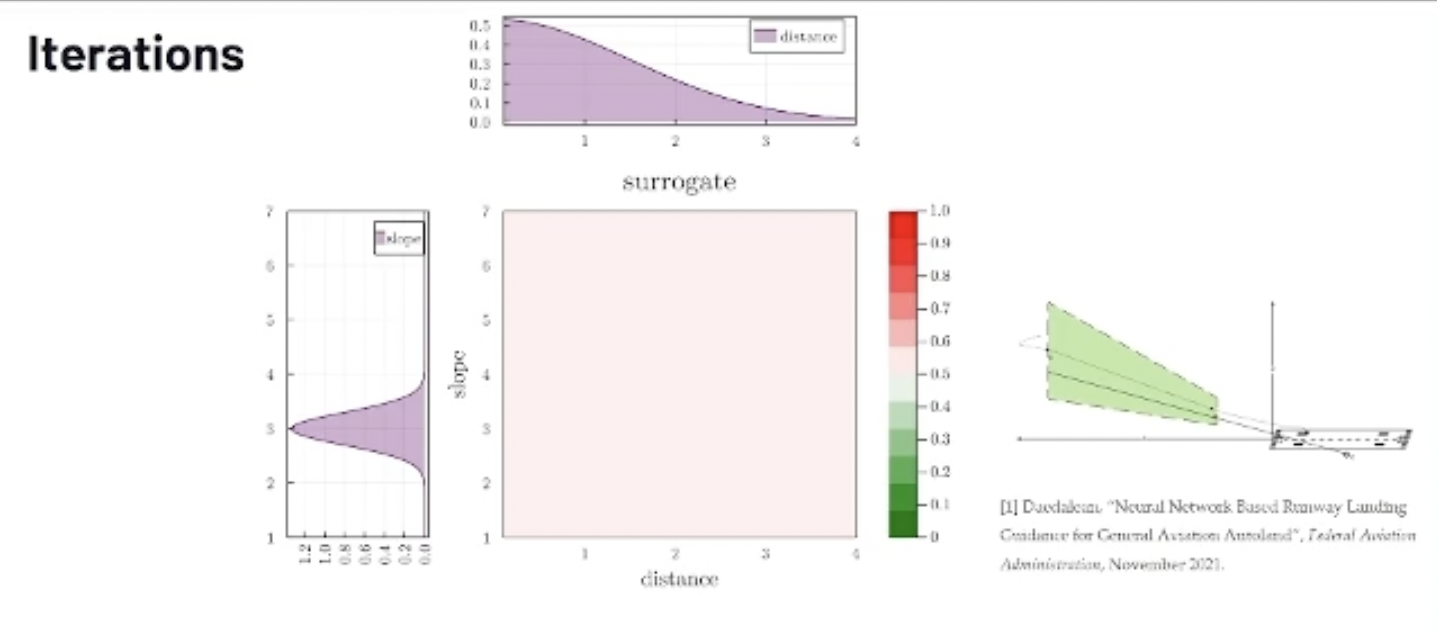
As I said, most pilots land the aircraft at around a three-degree glide slope, so that's most of the points concentrated in this area.
At Xwing, we try to operate the model pretty close to the runway. We're not going to try to dedicate the runway too far. This is where we concentrate most of our points, close to the runway.
What the algorithm does is basically start sampling. We start with three samples. All of those happened to be successes. The model correctly detected the runway in those samples, and that gives us an initial idea of where the failure boundary might be.

There's a lot of uncertainty in those regions because we don't have any samples. So the algorithm is going to try to sample there, and we have three more points.
And as you go, you keep adding those samples, and we already see a trend that a lot of points tend to accumulate here because we have more likelihood of operation, and also because the algorithm captures that there's a lot of variation of the model here from failure to success, so is concentrating most of the points there.

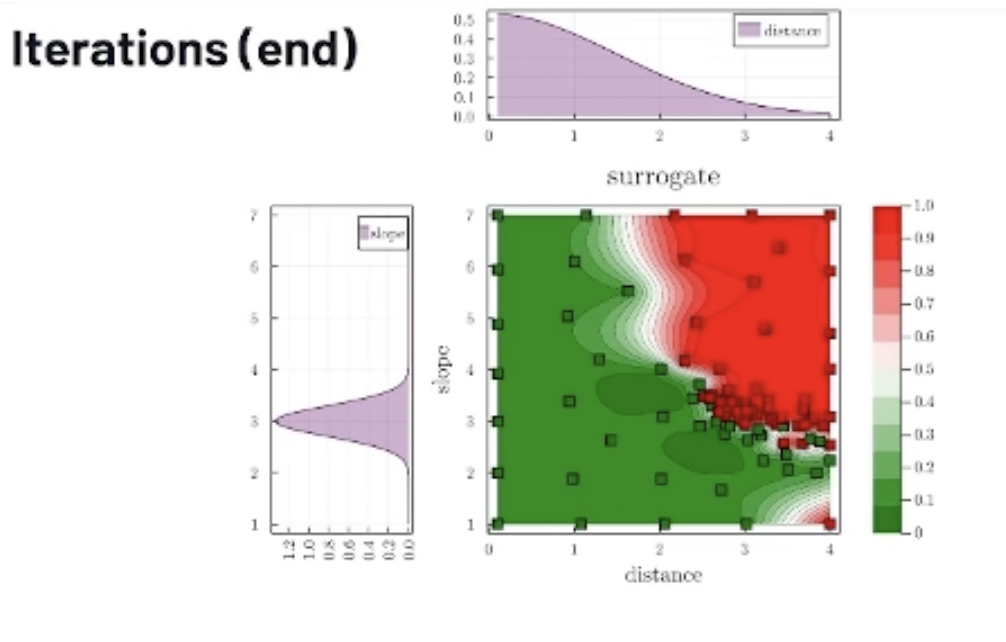
I'm going to go through a few more iterations. You can see that some points have also been added in the empty regions of the space to reduce the uncertainty.
This is the final iteration of the algorithm below. Again, we can see that accumulation of points here in that region, which is very critical. The model seems to change a lot between failure and success in this region of the space.
What can we do with that? We now have this hard failure boundary that you can see below. And if I compare that with where we’re expected to operate, we're left with the region where we know we want to operate, and the model fails. That gives us what we wanted: the probability of failure of the model.
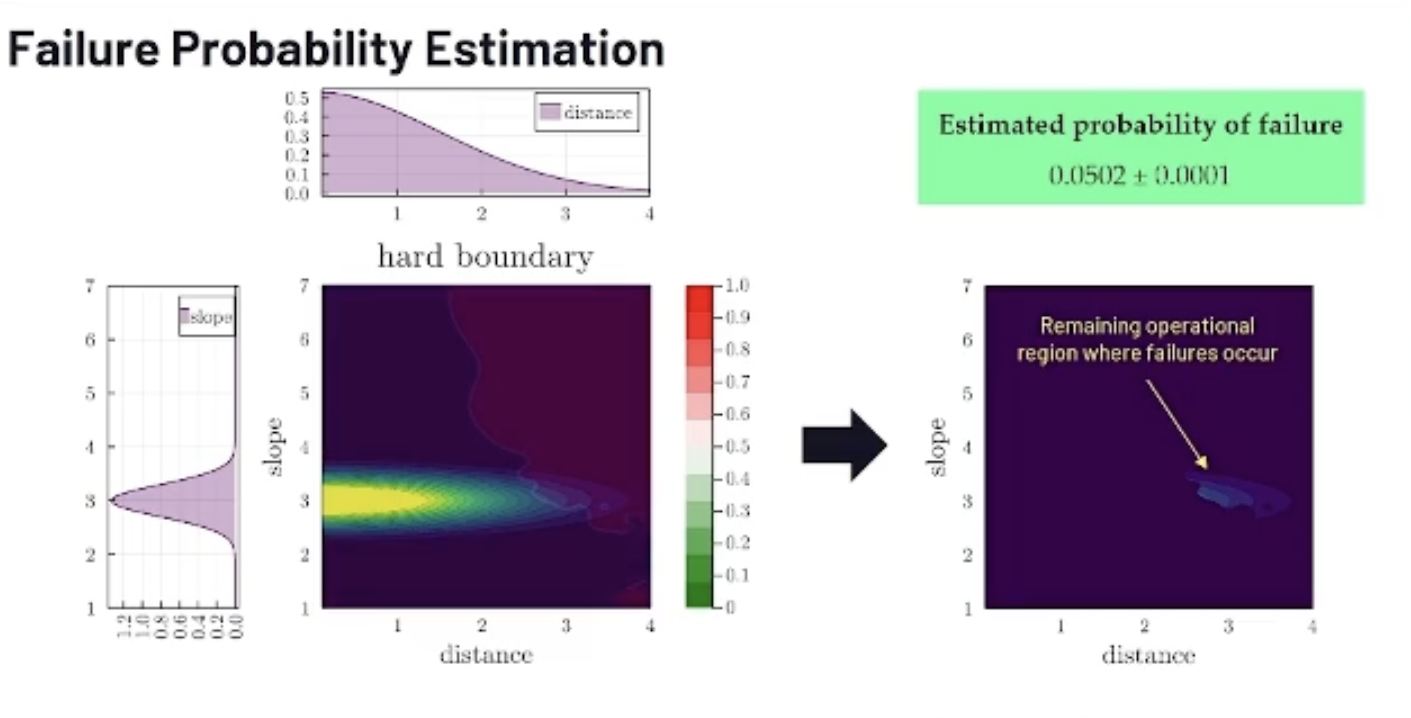
Here, that's the example of the type problem of 5%. If we try to compare that to our requirements of one failure per 100,000 approaches, we're not quite there yet. But the nice thing about the framework is that I'm going to show you how you can use it to improve that number and meet the certification requirements.
Another thing that this algorithm gives you is the most likely failure, where your model is expected to fail the most. And, interestingly, in the example below it's the point that corresponds to the image, which is three nautical miles from the runway and regular slope angle.

What can you do with the result?
With the first one we just did, we computed the probability of failure. The second one is that you can refine the operational domain. If you realize that your model fails most in a certain region, you can very much decide that you’re not going to operate in that region.
That corresponds to what I'm doing here. I can just say, “Well, we're always going to activate the runway detection below three nautical miles.” If I do that, we automatically see that most of the area becomes green, and we're left with very few failures. That might help us meet the requirements for certification.
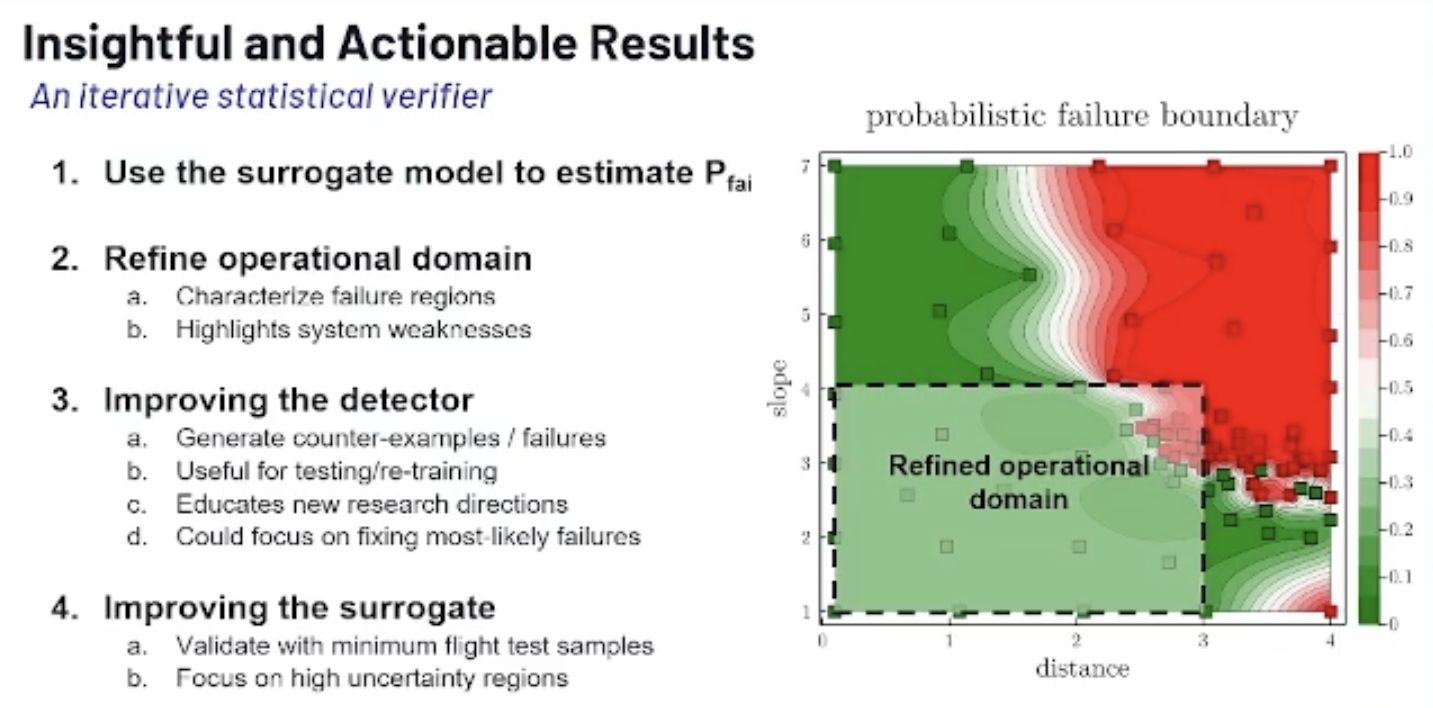
In the process of running the algorithm, you also generate a whole bunch of failure examples. You can use those to train the model in that region so that region then becomes green.
Finally, you could validate all of that data with an actual test flight to go and collect those sample points in real life as well improve your confidence in the estimate.
Robert Moss’ paper looked at comparing this approach to different sampling schemes. We have the discrete one that we used initially with regular space points,
What came out of the comparison with those different sampling schemes was that our algorithms showed more stability in the estimate of the true probability of failure, and also faster convergence. You get to prove your probability of failure with fewer samples.
We can imagine that those samples might be expensive to collect. If each sample is a flight and a test point, it might be pretty expensive to calculate and correct.
Summary
To summarise the key takeaways from the presentation, we take the system's approach to certify the machine learning onboard the aircraft.
Let's remember that it's only a very small component of the overall stack, and that's the small piece that you're trying to certify. The rest of the stack follows the traditional process.
You get an assigned probability of failure, and this is what you're trying to compute. For that, we introduced that statistical verifier algorithm that scales to the current big architectures that you have in the industry.
It's a black box approach, so it doesn't care about what model you're trying to evaluate. That makes it very modular and adaptable to different approaches.
We didn't consider every possible value for every pixel of the camera. We switched the vision from the pixel space of the sensor input space to this vision of operational domain space, where the aircraft is operating more than what the sensor’s going to see.
Currently, we're working on ways to show robustness between the different samples that we collect and have a little bit more robustness there. And we’re extending that approach to the many dimensions that we have in the parametric space.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

