
Most AI agent systems are built once and then repeat the same patterns indefinitely, like an employee who insists every problem can be solved with the same spreadsheet.
New research from Peking University proposes a more effective model: agents that accumulate working solutions as executable code, refine them with each new task, and become more capable over time.
The static agent problem
Most agent systems today follow a simple pattern. An agent receives a task, follows a prompt-defined process, produces output, and moves on.
When it encounters a similar task later, it often starts again from scratch, apparently having learned absolutely nothing from the experience.
Blueprints like AgentFactory, developed by researchers at Peking University and the Beijing Academy of Artificial Intelligence, take a different approach.
Instead of storing successful solutions as prompt tweaks or textual reflections, this kind of framework saves them as executable Python subagents: reusable pieces of code with standardized documentation that can be retrieved, adapted, and redeployed for future tasks.
The result is a system that improves over time:
- Its library of tools expands
- Repeated tasks require less effort
- Performance improves through reuse and refinement
Without further ado, here are seven signs your current setup would benefit from this type of architecture...

1. Your agents solve the same problems repeatedly from scratch
If your agent handles similar tasks across sessions and rebuilds its approach every time from a blank prompt, you are spending compute on work that already exists.
Modern architectures address this directly. When a new task arrives without a relevant subagent, the system builds one and saves it for future use.
The next time a similar task appears, the groundwork already exists.
2. Successful runs leave nothing behind
In many frameworks, a successful execution becomes a one-time event. The output is produced, logged, and forgotten.
If successful runs are not creating reusable capability, accumulated knowledge disappears after every session.
3. Your agents get better prompts but not better tools
Prompt engineering remains the default response when agent performance needs improvement:
- Adjust the instructions
- Add more context
- Refine the examples
- Repeat until morale improves
That can help, but it improves the reasoning layer rather than the execution layer.
Many frameworks nowadays modify the tools themselves. Using execution feedback, it improves existing subagents over time, making them more robust and reusable.

4. Re-running a task type requires rebuilding context every time
One of the hidden costs of static agent systems is context overhead.
For example, AgentFactory reduces this overhead by retrieving saved subagents for similar tasks, cutting down on repeated reasoning and setup work.
5. Your agent’s capabilities are tied to one platform
If your agent’s tools are tightly coupled to one framework or runtime, the work invested in building them stays trapped there.
Most of today’s subagents can be exported and run in any Python-capable environment.
Portable, documented code turns a tool into a long-term asset.
6. Performance plateaus after deployment
A well-calibrated static agent often performs strongly at launch and then levels off, much like a New Year’s gym membership.
Without a feedback loop that converts new tasks into improved tooling, capability growth slows quickly.
If your deployment curve flattens after the first few weeks, the absence of a self-improvement loop is probably the reason.
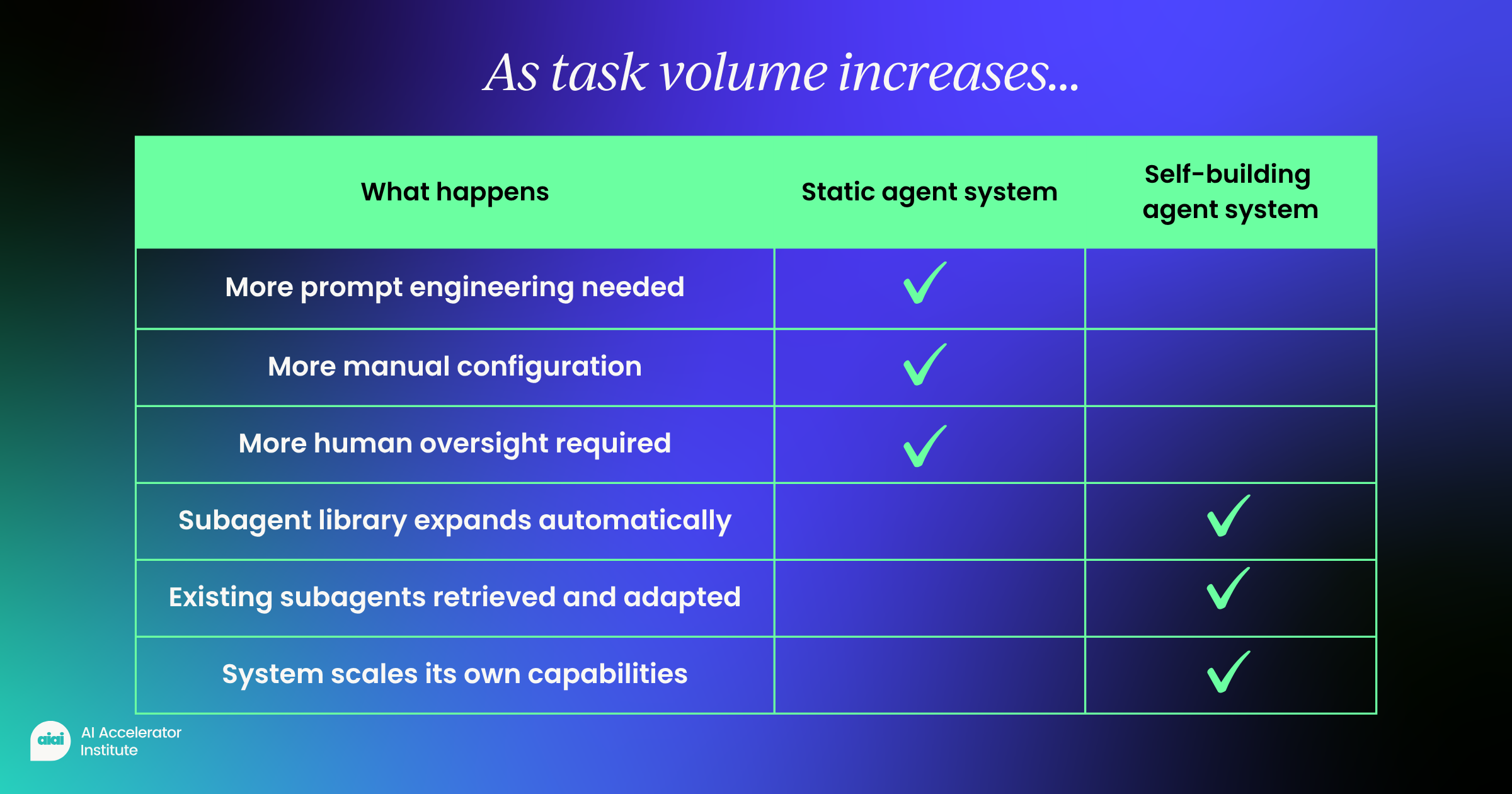
7. Scaling task volume means scaling manual maintenance
In many agent architectures, handling more task types requires:
- More prompt engineering
- More configuration
- More human oversight
What you should be looking to do is reverse that relationship.
As task volume increases, the subagent library should expand alongside it. A growing share of tasks can then be handled by retrieving and adapting existing subagents.
The system scales its own capabilities.
What this means in practice
This shift is not incremental. It introduces a different mental model for successful agent systems. Instead of a pipeline that runs tasks, you need an infrastructure that learns from them.
For teams building agentic AI systems, the practical takeaway is straightforward:
- Static agents are a starting point
- Reusable capability compounds value over time
- Systems improve fastest when every run produces something reusable
The most capable agent systems will not simply complete tasks. They will build a growing library of proven, portable capabilities that improve with every task they encounter.
Of course, self-improving agent systems come with tradeoffs. Persisting and modifying executable tools introduces questions around verification, security, version control, and failure propagation.
A system that can improve its own tooling can also reinforce bad patterns if the feedback loop is poorly designed.
Final thought
Static agents eventually hit a ceiling. Systems that create reusable tools, refine them through feedback, and carry those improvements forward operate very differently.
Every completed task becomes part of the system’s future capability instead of disappearing into the void five seconds later.
The long-term winners in AI may not be the systems that sound the smartest in a demo. They may be the ones that quietly get better every week while nobody is looking.
Source
Zhang, Z., Lu, S., Qian, H., He, D. and Liu, Z. (2026), “AgentFactory: A Self-Evolving Framework Through Executable Subagent Accumulation and Reuse”, arXiv:2603.18000. Published 18 March 2026.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

