
AI is an incredibly powerful tool that is solving more problems every day. It's also doing so more accurately, efficiently, and faster than ever before. But one challenge that's raised time and time again is, if you’re dealing with high-risk scenarios where people's lives are on the line, you need to be sure your algorithms make predictions and estimates based on sound principles.
So what's going on inside that black box? We need to know. And I'd like to walk you through a journey we've taken to try and move the needle on that.
Introducing COLIN - Counter Observational Latent InterrogatioN
The idea here is, rather than using some of the traditional methods of seeing where in an image an algorithm pays attention to make its decisions, we want to ask the algorithm to show us what it knows.
For example, if you're hiring and you want to know whether a candidate's good or not, you might be interested in how well they did in their exams - essentially metrics. But that's not the whole story. That's not where the hiring process finishes.
If you want a really good expert, you get them in for an interview and you interrogate their knowledge. It's not just about whether they answer questions well or not. A good candidate will answer in a way that shows you they have a good understanding. And that's what we want to do here.
Let's take the image of the goldfish below. We're going to call him Colin. The goldfish at the top is the original image of a real goldfish, and we want to look at an algorithm that has been trained to understand facial expressions or sentiments.
In order to do that, what we could do with COLIN, as a method, is give this image to our algorithm that understands facial expressions, and ask our add-on method called COLIN to counterfactually render this image so it now represents an angry goldfish.

And that is actually how I generated these images. They aren’t photoshopped, they’re generated using this method of counterfactual rendering. And this gives us an understanding of not just what an angry goldfish might look like, but also an understanding of the model.
If we look at the counterfactual rendering of the goldfish in the bottom right-hand corner, you can see his fins look quite spiky. The forward fin is raised and he's got a frown on his face. His lip is also starting to snarl.
All of this came from an algorithm that understood the sentiment. And this is telling me that it understands what “angry” looks like, but also that it understands what all these anatomical features are, how they’re analogous to human anatomy, and how they could be re-represented in a way that might suggest an emotion.
That's telling me a huge amount more than some AUCs on a metric of how well it can detect sentiment. So this is COLIN, and it’s a method we’re going to explore more in terms of:
- What it is
- Why it is
- How we got to it
Where did COLIN originate?
Activation maximization
So first things first, where did the COLIN method come from? You might be familiar with DeepDream, which came out of Google research and was one of the very first attempts at trying to understand what was going on inside the black box of AI.
The idea was essentially activation maximization, where you optimize the input or image to most strongly activate either a class or a neuron within the neural network and get some idea as to what’s going on there. What features would actually trigger the activation of a class or a neuron?
It was amazing. It produced images nobody had ever seen before. But as you can see in the example below, it's pretty psychedelic and a bit of a mess. You can't be absolutely certain what exactly in this image has triggered the activation, so it's not ideal.

In fact, it seems to fall foul of something that humans experience called pareidolia, the phenomenon where you look up into the clouds and start seeing an image in them. As soon as you see it, your imagination starts to paint the rest of the image. This method of activation maximization essentially falls foul of this a little too much and you end up with very psychedelic outputs.
But it was an interesting start and grabbed a lot of people's attention. And that's often what you need to get going with a good idea.
A year or two after this, we started to see work in a very similar method, but looking at it from a different end of the spectrum.
Many will be familiar with adversarial attacks. The idea is that you have a classifier, e.g. an image of a pig, that classifies it as a pig. But what if you could alter the image as little and as imperceptibly as possible to then activate a different class? In this example, the other class would be an airliner.

So the pig still looks like a pig but the classifier is now convinced that this is an airliner.
This of course caused a lot of concern, and people wanted to make algorithms more robust to deal with this. Again, It helped us move a little further forward in understanding the limits of algorithms, but it didn't really explain a huge amount as to what was going on inside them beyond that.
StylEx
If we step forward three or four years later, we start to see generative adversarial networks really coming into play and being used for this same process of trying to understand a classifier or a similar algorithm.
It's taking an image, putting it through a classifier and seeing what the class is according to the classifier, and then altering the image, this time with style transfer using generative adversarial networks.
The result is really impressive; features are being generated that are very realistic. Our example below is a retinal fundus image, a picture of the back of an eye. It’s often used to look at retinal disease and other systemic diseases. And the feature they've inserted into this image really does look like the kinds of features that you see.
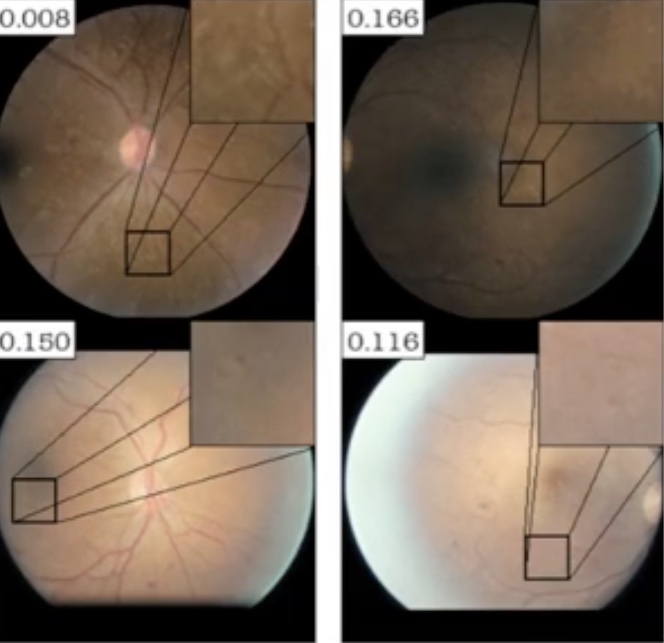
It's really impressive and it’s starting to feel promising. But there's a shortcoming, which I'll get to later.
Controlling the noise with diffusion models
Another year passes which brings another huge step forward in computer vision. Diffusion models are exploding onto the scene at the moment. Their story originates in reducing noise. The original idea was, what if you could take a noisy image and make it look like it's nice and clean and sharp?
It had a nice, simple premise to it that you could very easily generate datasets. All you need are images because you can always just add noise to the image. And now you've got a positive and a negative example.
OpenAI and others realized that you could take this to an extreme. You could basically keep training it and adding more and more noise to the point where it would try to go back to some kind of coherent image. And you could then guide it and add some kind of condition.
In the example below, we can see they've masked out an area in green to say, “Okay, we’ll add a bunch of noise to this area and then denoise it, but whilst you're denoising we also want you to meet this other condition.”

This other condition was imposed on a joint embedding, which was a language embedding. And they fed it to the condition to say, “There needs to be a vase of flowers in this.” So when it filled in this green region, it had to meet this condition. And it made this beautiful vase of flowers sitting on the table.
This is obviously a very impressive feat. You've got a reflection and shadow and all sorts of really nicely integrated visual features that look like they should be there. It's a very natural-looking image.
So job done, right? If you can just ask an algorithm to show you what a counterfactual example of something looks like and it can do a job like this, then surely we've solved the problem?
Not so much.
Both generative adversarial networks (GANs) and diffusion models are, in themselves, black boxes. So if you're adding a black box to try and solve the problem of what's going on inside your black box, you haven’t solved the problem. You've just added more problems. And you don't know how much of the signal is now coming from that adversarial network or diffusion model.
This is where COLIN kicked in.
We wanted to do the same trick but without any additional latent spaces.
Improving the regularization of activation maximization with the COLIN method
I started with a goldfish because they happen to be the first class in ImageNet. I then looked to the next closest class which was a tiger shark. Next, I gave myself the task of taking a classifier that knows what a goldfish and a tiger shark look like, and using it to counterfactually render this image of the goldfish into a tiger shark and see what we learn.
This is essentially DeepDream, which is the approach of optimizing the input to maximize a class.
I started by looking at better regularization, better model choices, and better optimization algorithms, and what I found was that you could get a long way by just choosing the best options of all of those. We then started to see shark-like features.
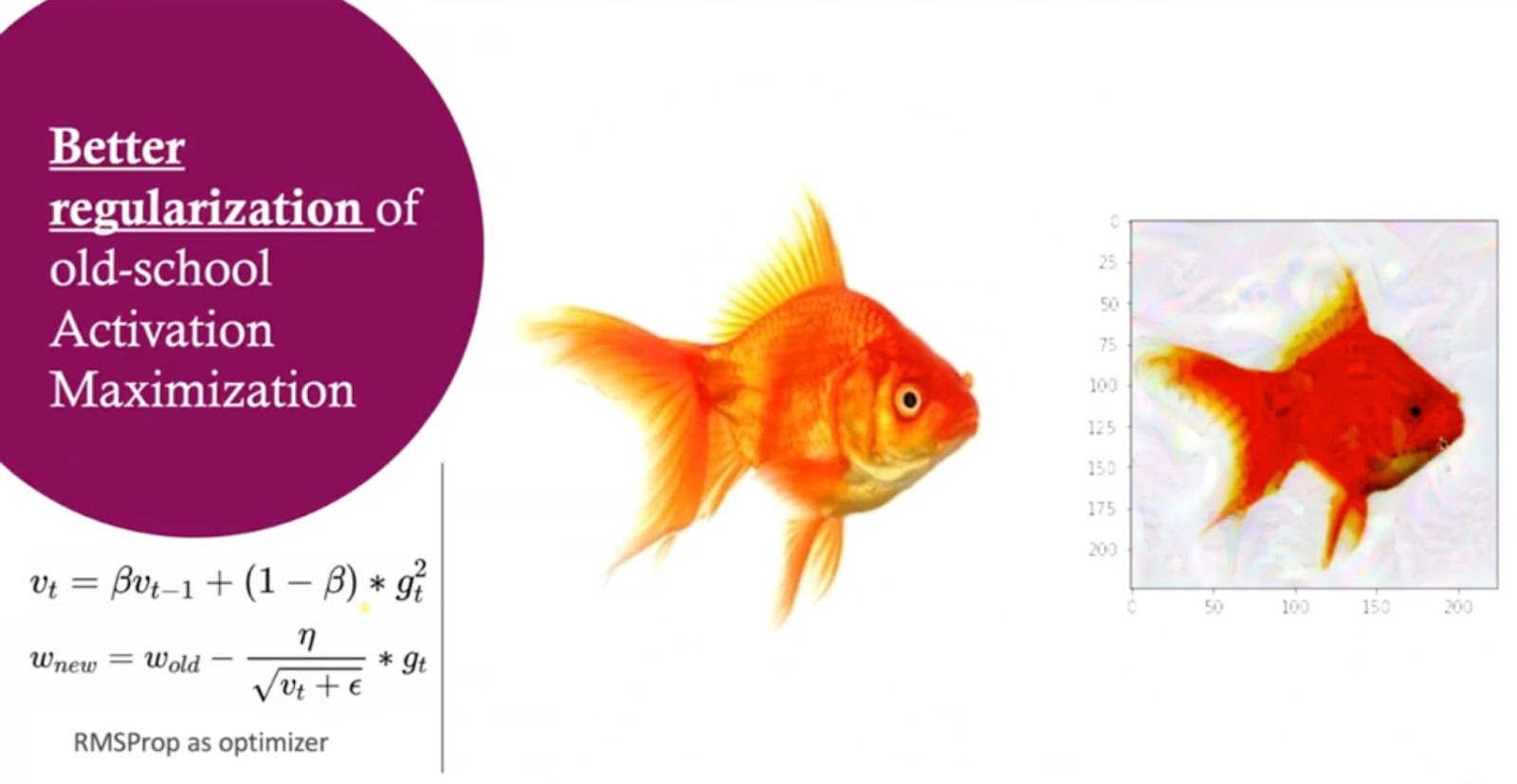
Colin is starting to look like he's got a shark-like face in the output on the right-hand side of the above image. We’re getting somewhere with this, but you’ve probably noticed it's still gold. Sharks aren't gold.
This was my first insight ever gained from using the COLIN method. The algorithm that I picked off the shelf and downloaded from GitHub had been trained with color jitter augmentation, so it was actually colorblind. Therefore, it wasn’t surprising that it didn't alter its color when I asked it to tell me what a shark looked like.
The second insight was that it was still the wrong shape. All the features were there or starting to come in, but Colin was still goldfish shaped in the perimeter. So this got me looking into some of the properties of convolutional neural networks.
Transformers might be better in this regard, in that they have some idea of distance. In contrast, convolutional neural networks have less of an understanding of the perception of relative distances between features.
So what happens if you take the same model but just use a deeper version of it? Now we're going up to the EfficientNetB5 where we start to see more detail, but we also see it's harder to control that psychedelia; the background’s starting to get a little wacky here.

Yes, I'm starting to see patternation on the fish, but I'm also seeing it in the background. That's a problem we're going to have to fix.
But here's another insight emerging, probably the first insight that I got of the real world from this method. Tiger sharks are mostly spotty, not stripy, and I noticed that spots were appearing on Colin. A few stripes, but more spots. So, I'm starting to learn things about the real world via this explanation method.
What about other models? VGG16 seems to perform similarly to EfficientNet81, which is surprising as they're very different architectures.

Inception v3 was quite bad as you can see below. The goldfish hardly changed at all. So what might be going on there?

We're wondering if some architectures that are less equivariant and less adapted to semantic segmentation tasks aren’t going to do so well with the COLIN method.
We believe this is because it's very difficult to work backward and attribute a single pixel to a given activation further up the chain. That is, if in the middle of the architecture you've got it’s splitting into different blocks. Each has a different resolution, so you're losing track of where the signal is coming from at a pixel level. So that's a challenge to be aware of.
The diffusion models are brilliant, so can we learn from those without adding a black box? And the answer was: yes we can.
Learning from the success of diffusion models
We tried to take as many tricks from diffusion models as we could without adding new latent space. We applied it to medical challenges, and what we discovered was that it worked amazingly well.
Below is an original retinal image in the top left. We ran it through COLIN for multiple iterations and made a video of what happened next. And what we saw was that the veins in the back of the eye got shorter and shorter.
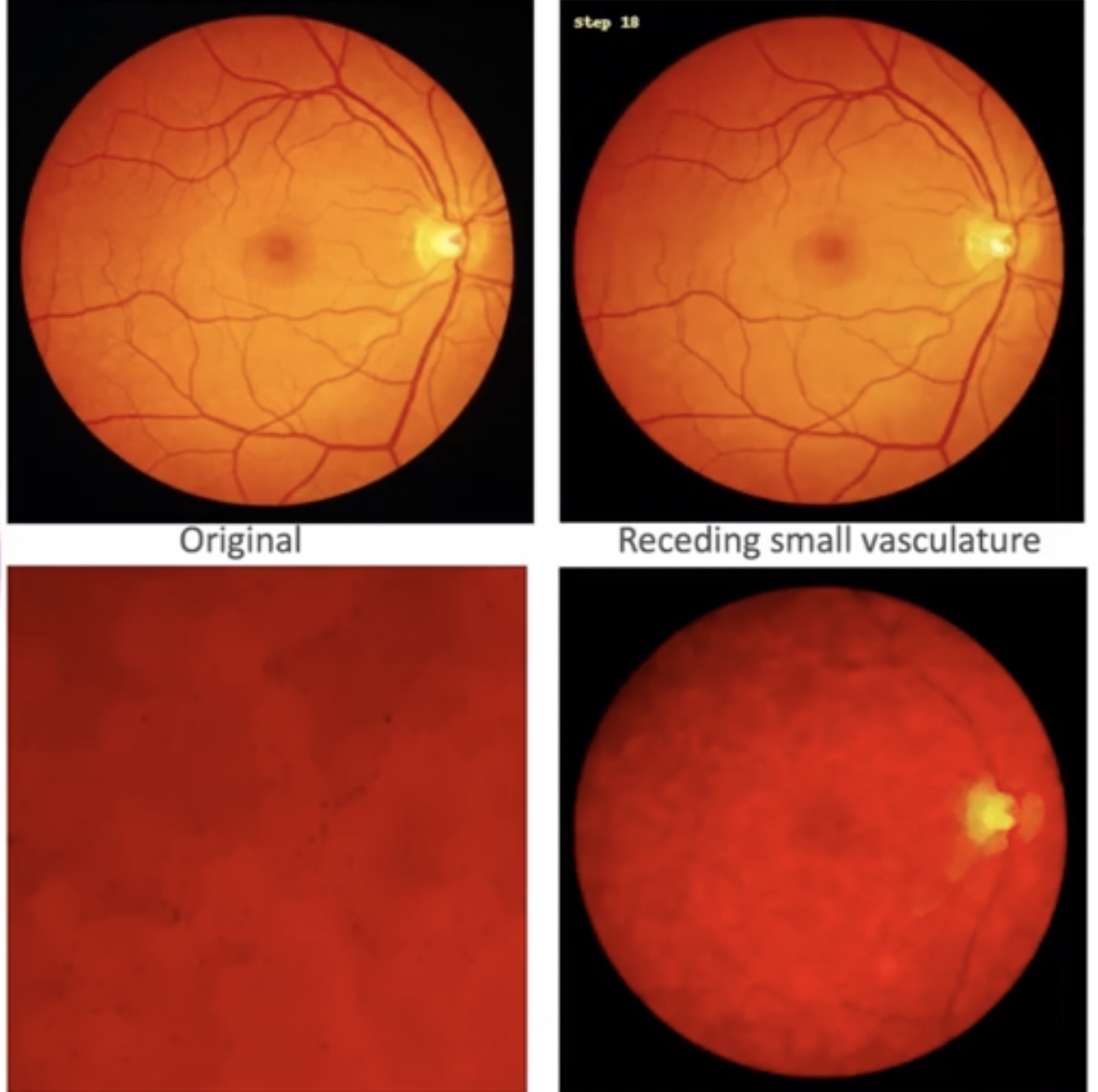
And sure enough, when I asked experts in this field, they said, “Yes, this is something we're expecting to see because the condition that the model has been trained to detect causes a dying off of the small vessels.”
But when I zoomed in, it also showed lots of little black spots which are very similar to microaneurysms, tiny bleeds in the eye. There is significant evidence to suggest that the same condition causes these visual findings as well. This has now taught me something about medicine and that makes it very valuable to me.
It works for pathology as well, which is also incredibly valuable to us at AstraZeneca. Here, we've got a real example of an unhealthy sclerotic glomerulus on the bottom left, and a counterfactually rendered healthy example as though it were unhealthy and sclerotic on the bottom right. So again, it's teaching us about things that we’re not super familiar with.

It also works incredibly well with photography. We looked at atopic dermatitis or eczema. The real, healthy image below is on the left, and the counterfactually rendered image is on the right. And again, it's telling us that the algorithm is fully aware of what it looks like. It knows what the rash looks like and where it's going to be, which is on the palm of the hands and in the joints where people scratch the most.
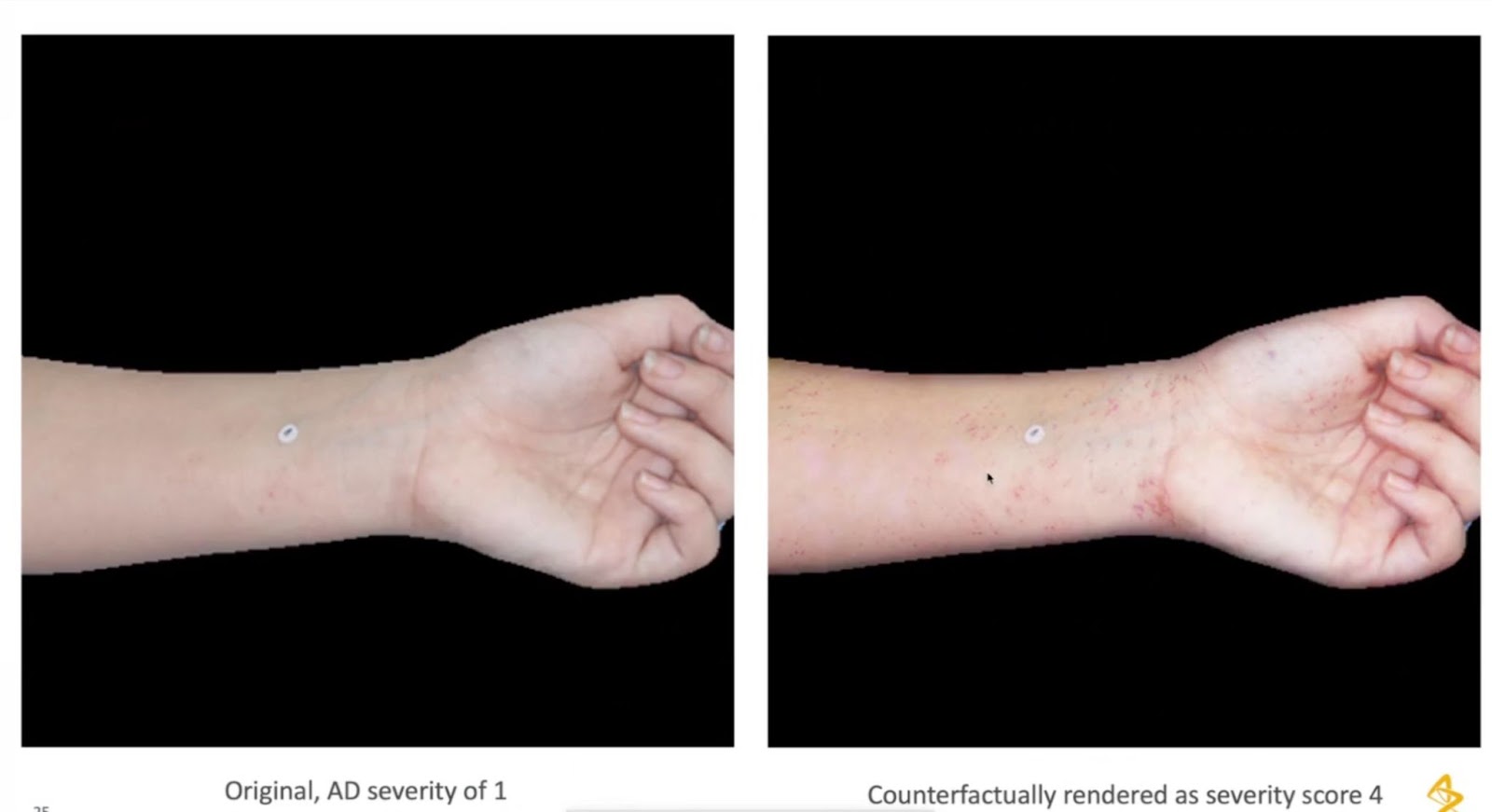
Another nice thing about this is that you can give it one input, and then you can seed and reseed it until it gives you many examples of what the disease might look like. For example, if I rerun an image of a skin condition with a different, random seed, it can show rashes and all sorts of visual findings that are common to severe eczema.
The very last example I want to show you was super interesting. Wilson's disease is a rare condition where your liver fails to metabolize copper, and copper builds up in your body. One way to diagnose it is to look at the iris of your eye. Essentially, the copper builds up in there and you can see it.
We set off thinking we were going to see rings or see some kind of darkening, so we had an assumption going in. Example A below is a healthy eye, and example B is the counterfactual rendering of that as though it had Wilson's disease.
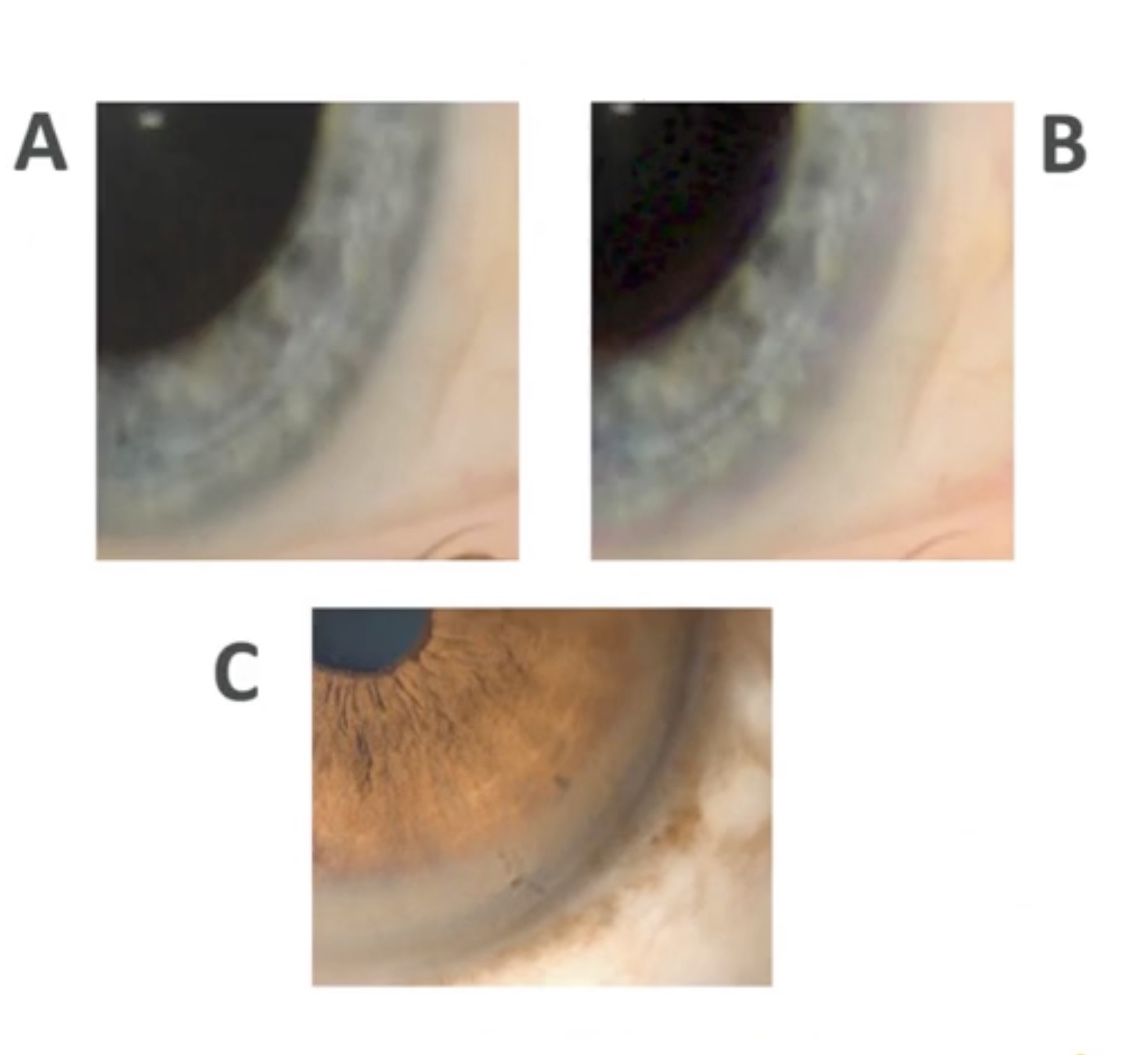
You can see that the natural ring around the iris is patterned and dark, but it gets hidden and vanishes. This really surprised us, we thought maybe it was broken.
We went and looked at the examples again, and actually, the most significant thing in the real examples of the condition was the natural patternation of the iris getting hidden by the copper. And so the coloration that might occur is less significant than the fact that the patternation of the eye gets hidden.
Again, we've learned something about the algorithm and we’ve learned something about the condition itself.
So what does COLIN show us?
We learned a lot from diffusion; we add blur, we optimize, add blur, then optimize, and we keep doing this until we get a natural-looking image building up.
We've learned that classifiers do not perceive the world as we always assume. They might be colorblind, there might be all kinds of things we don't know until we look and ask them.
Some architectures are more conducive to explainability than others. We didn't know which ones until we went looking. As such, this is building more and more interest in diffusion.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

