
Whenever we speak about model prediction, it is essential to comprehend prediction errors (bias and variance). There is a tradeoff between a model’s ability to minimize bias and variance. Gaining a proper understanding of these errors would help us to build accurate models and prevent the risk of overfitting and underfitting.
So, let's begin with the basics and what difference they make to our machine learning models.
What is bias?
Bias is the deviation between the average prediction in the model and the correct value that we are attempting to predict. Models with high bias pay little attention to the training data and the model becomes oversimplified. It always leads to high errors in training and test data.
What is variance?
Variance is the variability of model prediction for a given data point or a value that tells the spread of data. Models with high variance pay a lot of attention to training data and don't generalize on the data that it has never seen before. Such models perform well on training data but have high error rates on test data.
Mathematically
Let the variable we are trying to predict as Y and other covariates as X. We assume there is a relationship between the two such that.
Y=f(X) + e
Where e is the error term, and it is normally distributed with a mean of zero.
We have a model f^(X) of f(X) using linear regression or any other modeling technique.
So, the expected squared error at a point x is.
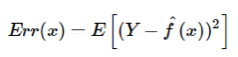
The Err(x) can be further decomposed as
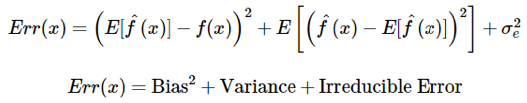
Err(x) is the sum of Bias², variance, and the irreducible error.
Irreducible error is an error that cannot be reduced by creating good models. It is a measure of the amount of noise in our data. Here it is vital to understand that no matter how good we make our model, our data will have a certain amount of noise or irreducible error that cannot be removed.
Bias and variance using a bullseye diagram
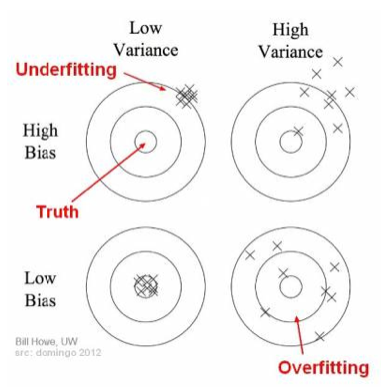
In the above diagram, the center of the target is a model that perfectly predicts correct values. As we move away from the bullseye the predictions become worse and worse. We can repeat our process of model building to get separate hits on the target.
In supervised learning, underfitting happens when a model is unable to capture the underlying pattern of the data. These models usually have high bias and low variance. It happens when we have little amount of data to build an accurate model or when we try to build a linear model with nonlinear data. These kinds of models are quite simple to capture the complex patterns in data like Linear and logistic regression.
In supervised learning, overfitting happens when the model captures the noise along with the underlying pattern in data. It happens when we train our model a lot over noisy dataset. These models have low bias and high variance. These models are complex like Decision trees which are prone to overfitting.
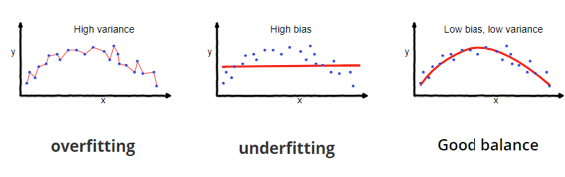
Why an understanding of the Bias Variance Tradeoff is essential
If our model is too simple and has very few parameters, then it may have high bias and low variance. On the other hand, if the model has a substantial number of parameters, then it is going to have high variance and low bias. So, we need to find the right balance without overfitting and underfitting the data.
This tradeoff in complexity is why there is a tradeoff between bias and variance. An algorithm cannot be more complex and less complex at the same time.
Total error
To build a good model, we need to determine a fine margin between bias and variance such that it minimizes the total error.
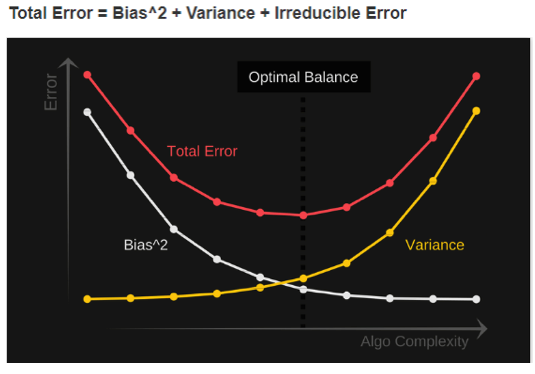
An optimal balance of bias and variance would never overfit or underfit the model.
Therefore, comprehending bias and variance is critical for understanding the behavior of prediction models.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

