
Imagine, you are trying to find some articles or papers for your assignment or are trying to figure out how to fix a particular problem at work. What is the first thing you do? Open Google and search for relevant information.
It can be exhausting to go page by page and look for the required data. Seeing an increase in the availability of vast amounts of textual social media data online has led enterprises and their teams to utilise machine learning and natural language processing algorithms.
Among these techniques, topic modelling has emerged as a popular method for analysing and extracting valuable insights from this extensive corpus.
Topic modelling is an unsupervised machine learning method that can analyse a collection of documents, identify patterns of words and phrases, and automatically group them into clusters based on their similarity. This technique enables the identification of word groups and expressions that effectively capture the essence of a given set of documents.
This article explores the importance of topic modelling. We will start with some basics and slowly dive into practical hands-on exercises to learn about existing topic modelling algorithms. Further, this article talks about some advanced techniques but before delving into the technical details, let's review some fundamental concepts.
Understanding topic modelling
The documents are composed of a mixture of topics, and each topic consists of a set of related words. For instance, a group of words such as 'patient,' 'doctor,' 'disease,' diabetes,' and 'health' could indicate the topic of 'healthcare.'
Topic modelling algorithms aim to uncover these latent topics by analysing the distribution of words across documents. Using Topic Modelling we can extract co-occurring keywords for succinctly summarising vast amounts of textual data and uncover concealed themes within documents. This is how it facilitates the annotation of documents based on those themes and aids in organising extensive unstructured data.
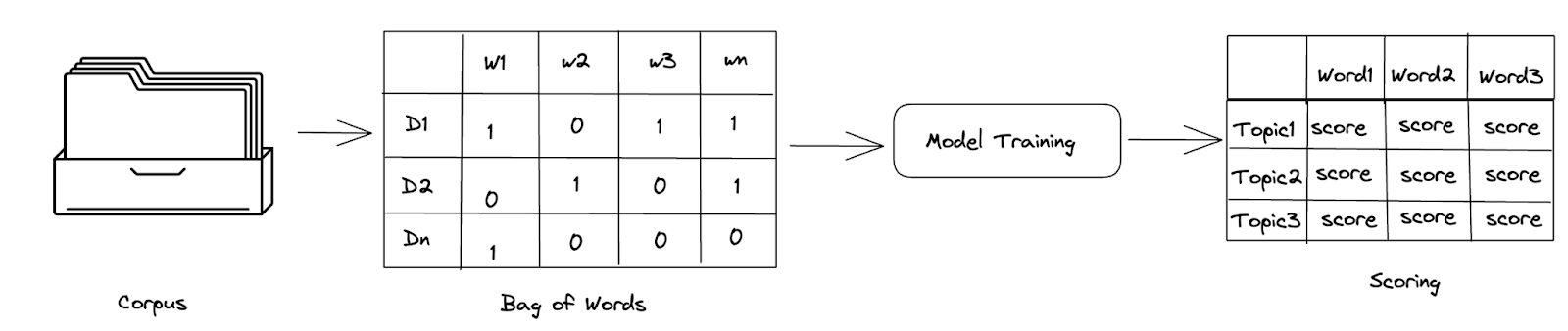
There are many topic modelling techniques and they can be categorised under two groups - Non-Probabilistic and Probabilistic. The probabilistic model is more popular as it helps to improve the algebraic model by adding generative model approaches. One of the widely known topic modelling algorithms is LDA - Latent Dirichlet Allocation.
Latent Dirichlet Allocation: A topic model
Latent Dirichlet Allocation (LDA) is a probabilistic topic modelling technique that assumes that each document in the collection is a mixture of multiple topics.
Each topic is characterised by a probability distribution over words, meaning certain words are more likely to appear in documents about a specific topic. The distribution of topics in a document and the choice of words within that document are both governed by probability distributions, which means the LDA model is able to infer topics from a given collection of documents without relying on any prior knowledge or input.
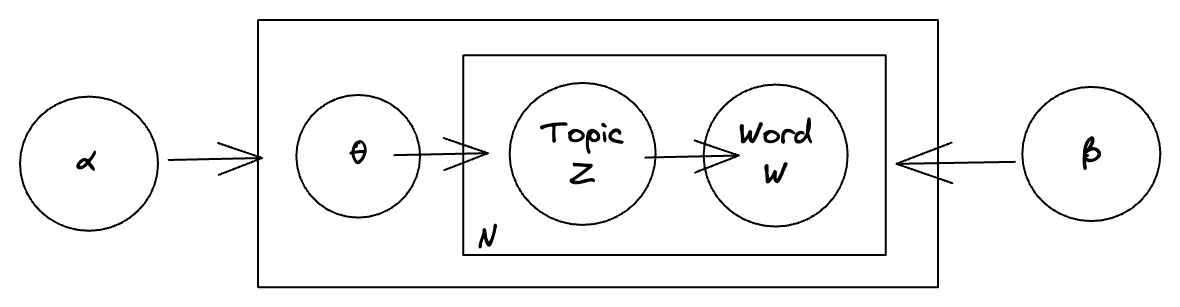
Where,α - Dirichlet prior to document topic distribution
θ - Topic distribution over a document
z - Topics for a particular word in a document
w - Chosen words among all number of words in a document
N - Number of words in the document
β - Dirichlet for the word distribution
In LDA we calculate word-topic probabilities, reassign words to topics, and update topic-word and document-topic distributions until a maximum number of iterations is reached. Once you have the final distribution, interpret and analyse the topic-word distribution to understand the discovered topics based on the most probable words associated with each topic.
Applications of topic modelling
Topic modelling has found numerous applications across various domains due to its ability to uncover hidden themes in text data. Some of the key applications of topic modelling include:
Document clustering and organization - Topic modelling can be used to automatically group similar documents together based on their shared topics. This aids in organising large document collections, improving information retrieval, and facilitating content recommendation systems.
Information retrieval and recommendation systems - By identifying the main themes within documents, topic modelling helps improve search and recommendation algorithms by matching user queries or preferences with relevant topics instead of relying solely on keyword matching.
Text summarization - Topic modelling can be leveraged to generate summaries of large text collections by extracting the most representative topics and key phrases within each document. This aids in providing concise overviews of lengthy documents or assisting in generating abstracts.
Trend analysis and social media monitoring - Topic modelling enables the identification and tracking of emerging trends or popular topics in real-time by analysing text data from social media platforms, news articles, or online forums. This helps businesses, researchers, and marketers stay updated with current discussions and sentiments.
Customer reviews and feedback analysis - Topic modelling can be applied to analyse customer reviews, feedback, or survey responses. It helps in identifying the main themes or topics discussed by customers, allowing businesses to gain insights into customer preferences, sentiment analysis, and areas for improvement.
Content categorization and tagging - By assigning topics to documents, topic modelling aids in automatically categorising or tagging content, making it easier to organise and retrieve information. This is particularly useful in content management systems or information-intensive platforms.
Fraud detection and anomaly detection - Topic modelling can assist in detecting fraudulent or anomalous behaviour by identifying unusual patterns or topics that deviate from the norm. This is applicable in areas such as cybersecurity, finance, or online community moderation.
Research and literature analysis - Topic modelling supports researchers in exploring and analysing large volumes of scientific literature. It helps in identifying key research areas, uncovering relationships between different topics, and facilitating knowledge discovery.
These are just a few examples of the wide-ranging applications of topic modelling. With its ability to extract meaningful topics and uncover hidden structures within text data, topic modelling continues to be a valuable tool in various fields for organising, analysing, and gaining insights from large textual datasets. Let’s see how it is actually done.
Uncovering hidden structures: Hands-on exercise
In the previous sections, we talked about the basics of topic modelling and what LDA is and how it works. Here we are going to follow the steps when using the LDA model for generating topics across documents:
Data load & preprocessing: We will load the data and then remove unnecessary characters, punctuation, and special symbols, as well as convert the text to lowercase.
Here we will tokenize the data to split the text into individual words or tokens. We will be removing stop words, which are common words that lack meaningful significance
Create a document-term matrix: We will count the frequency of each term (word) in each document and create a matrix where each row represents a document, and each column represents a term, with the corresponding frequency.
Define helper functions: To identify the topics
Apply LDA algorithm: We need to specify the number of topics (k) to be identified. Next, each word in each document is randomly assigned to one of the k topics. Then, an iterative process begins where each word is reassigned to a topic based on probabilities. This process continues until convergence, where topic proportions for each document and word distributions for each topic are calculated.
Evaluate and interpret the results: Topic categories can be characterised by their most frequent words.
Common challenges & limitations
Topic modelling is a powerful technique for uncovering latent themes in text data, but it also faces certain challenges. Here are some common challenges associated with topic modelling:
Determining the optimal number of topics - Selecting the appropriate number of topics (K) is a subjective task. If the number of topics is too low, important subtopics may be overlooked. Conversely, if the number is too high, topics may become too fine-grained and less interpretable.
Overlapping topics - Words can have multiple meanings or be associated with multiple topics, leading to ambiguity. Additionally, topics can overlap, making it difficult to assign documents to a single topic or distinguish between similar topics.
Preprocessing and data quality - Topic modelling heavily relies on the quality of the input data. Noisy or unclean data, including spelling errors, inconsistent formatting, or incomplete sentences, can hinder the accuracy and coherence of the extracted topics.
Sensitivity to hyperparameters - Topic modelling algorithms, such as LDA, require setting hyperparameters like alpha and beta, which control the topic distribution within documents and the word distribution within topics, respectively. The choice of hyperparameters can significantly impact the quality and coherence of the generated topics.
Scalability - Topic modelling algorithms may face scalability issues when applied to large text corpora. Processing large datasets requires computational resources and efficient algorithms to handle the increased computational complexity.
Evaluation metrics - Evaluating the quality of generated topics is subjective and challenging. Metrics like topic coherence or human evaluation may be used, but they do not always capture the true semantic relevance or interpretability of topics.
Addressing these challenges often requires careful consideration of data preprocessing techniques, parameter tuning, incorporating external knowledge, and selecting appropriate evaluation strategies.
Conclusion
Throughout this article, we discussed the importance of topic modelling and its application in analysing large text collections. We also dwell into the steps involved in using the Latent Dirichlet Allocation (LDA), model for generating topics across documents. We also briefly covered the challenges and limitations of topic modelling and how we can overcome those.
There are a lot of other things that can be done to take a step further in learning about topic modelling;
- Interpreting and visualising Topics using word clouds, topic coherence graphs
- Topic modelling with metadata and document attributes
- Dynamic topic modelling for temporal analysis
- Incorporating deep learning approaches into topic modelling


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

