
Data pipelines are critical for organizations handling vast amounts of data, yet many practitioners report challenges with responsiveness, especially in data analysis and storage.
Our latest generative AI report revealed that various elements within the pipeline significantly affect performance and usability. We wanted to investigate what could be affecting the responsiveness of the practitioners who reported issues.
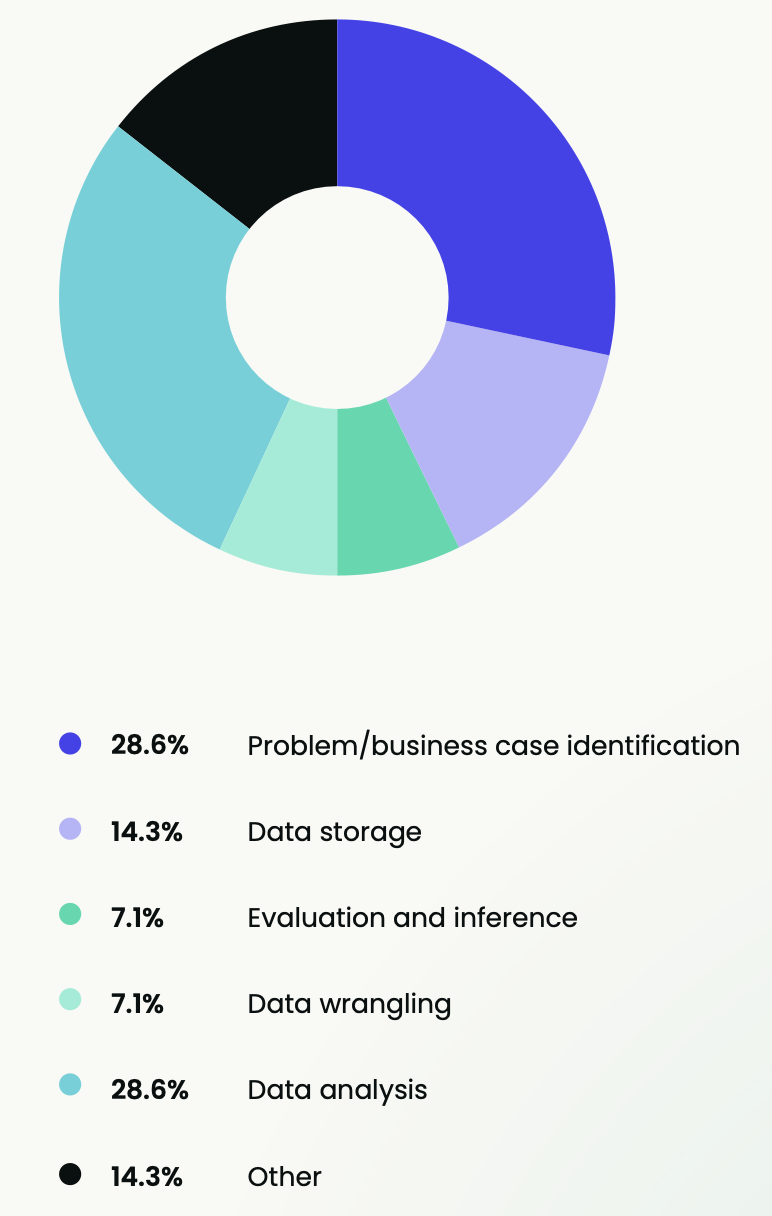
The main area of data workflow or pipeline where practitioners find the least responsiveness is data analysis (28.6%), followed by data storage (14.3%) and other reasons (14.3%), such as API calls, which generally take a significant amount of time.
What factors have an impact on that portion of the data pipeline?
We also asked practitioners about the factors impacting that portion of the pipeline. The majority (58.3%) cited the efficiency of the pipeline tool as the key factor. This could point to a pressing need for improvements in the performance and speed of these tools, which are essential for maintaining productivity and ensuring fast processing times in environments where quick decision-making is key.
With 25% of practitioners pointing to storage as a significant bottleneck after the efficiency of the pipeline tool, inadequate or inefficient storage solutions can impact the ability to process and manage large volumes of data effectively.
16.7% of practitioners highlighted that code quality disrupts the smooth operation of AI pipelines. This can lead to errors, increased downtime, and complicated maintenance and updates.
Code quality
The quality of the code in the data pipeline is key to its overall performance and reliability. High-quality code often leads to fewer errors and disruptions, translating to smoother data flows and more reliable outputs.
Examples of how high code quality can enhance responsiveness:
- 1. Error handling and recovery
- 2. Optimized algorithms
- 3. Scalability
- 4. Maintainability and extensibility
- 5. Parallel processing and multithreading
- 6. Effective resource management
- 7. Testing and quality assurance
Efficiency of pipeline tool
Efficient tools can quickly handle large volumes of data, helping to support complex data operations without performance issues. This is an essential factor when dealing with big data or real-time processing needs, where delays can lead to outdated or irrelevant insights.
Examples of how the efficiency of pipeline tools can enhance responsiveness:
- Data processing speed
- Resource utilization
- Minimized latency
- Caching and state management
- Load balancing
- Automation and orchestration
- Adaptability to data volume and variety
Storage
Storage solutions in a data pipeline impact the cost-effectiveness and performance of data handling. Effective storage solutions must offer enough space to store data while being accessible and secure.
Examples of how storage can enhance responsiveness:
- Data retrieval speed
- Data redundancy and backup
- Scalability
- Data integrity and security
- Cost efficiency
- Automation and management tools
- Integration capabilities
What use cases are driving your data pipeline?
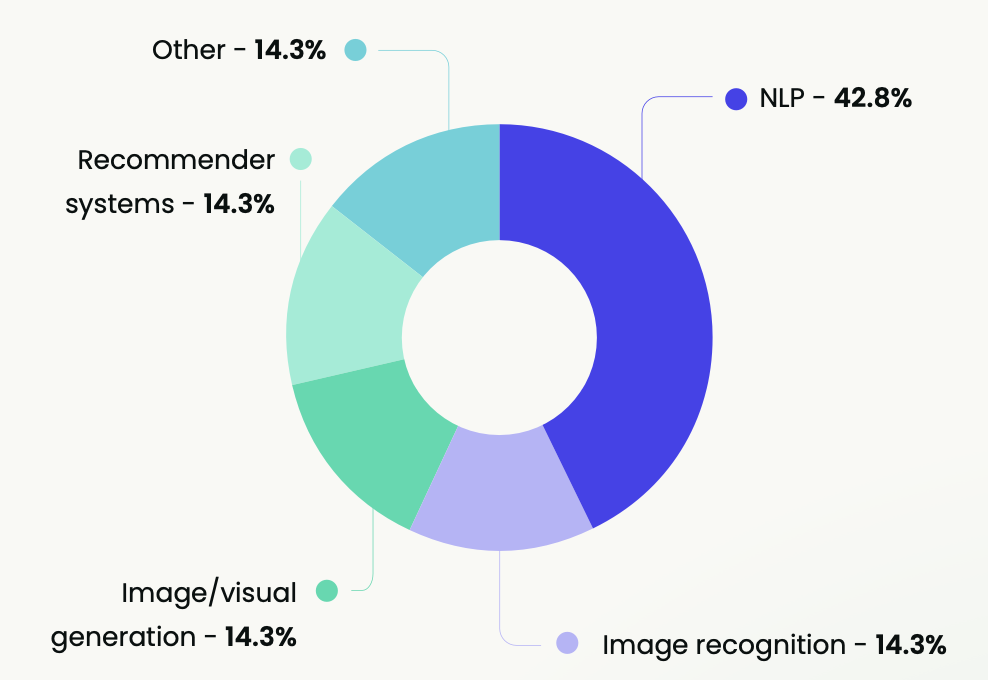
We also asked respondents to identify the specific scenarios or business needs that drive their data pipelines' design, implementation, and operation to understand the primary purposes for which the data pipeline is being utilized within their organizations.
Natural language processing, or NLP, was highlighted as the main use case (42.8%), with an even distribution across the other use cases. This could be due to businesses increasing their operations in digital spaces, which generate vast amounts of textual data from sources like emails, social media, customer service chats, and more.
NLP
NLP applications require processing and analyzing text data to complete tasks like sentiment analysis, language translation, and chatbot interactions. Effective data pipelines for NLP need to manage diverse data sources like social media posts, customer feedback, and technical documents.
Examples of how NLP drives data pipelines:
- Extracting key information from text data
- Categorizing and tagging content automatically
- Analyzing sentiment in customer feedback
- Enhancing search and discovery through semantic analysis
- Automating data entry from unstructured sources
- Generating summaries from large text datasets
- Enabling advanced question-answering systems
Image recognition
Image recognition analyzes visual data to identify objects, faces, scenes, and activities. Data pipelines for image recognition have to handle large volumes of image data efficiently, which requires significant storage and powerful processing capabilities.
Examples of how image recognition drives data pipelines:
- Automating quality control in manufacturing
- Categorizing and tagging digital images for easier retrieval
- Enhancing security systems with facial recognition
- Enabling autonomous vehicle navigation
- Analyzing medical images for diagnostic purposes
- Monitoring retail spaces for inventory control
- Processing satellite imagery for environmental monitoring
Image/visual generation
Data pipelines are designed to support the generation process when generative models are used to create new images or visual content, such as in graphic design or virtual reality.
Examples of how image/visual generation drives data pipelines:
- Creating virtual models for fashion design
- Generating realistic game environments and characters
- Simulating architectural visualizations for construction planning
- Producing visual content for marketing and advertising
- Developing educational tools with custom illustrations
- Enhancing film and video production with CGI effects
- Creating personalized avatars for social media platforms
Recommender systems
Recommender systems are useful in a wide variety of applications, from e-commerce to content streaming services, where personalized suggestions improve user experience and engagement.
Examples of how recommender systems drive data pipelines:
- Personalizing content recommendations on streaming platforms
- Suggesting products to users on e-commerce sites
- Tailoring news feeds on social media
- Recommending music based on listening habits
- Suggesting connections on professional networks
- Customizing advertising to user preferences
- Proposing travel destinations and activities based on past behavior
Want more valuable insights about how end users and practitioners are using generative AI tools?
Download the entire report below.



AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

