
In the field of machine learning, there are two approaches: supervised learning and unsupervised learning. In this article, we will explore the concepts of supervised and unsupervised learning and highlight their key differences.
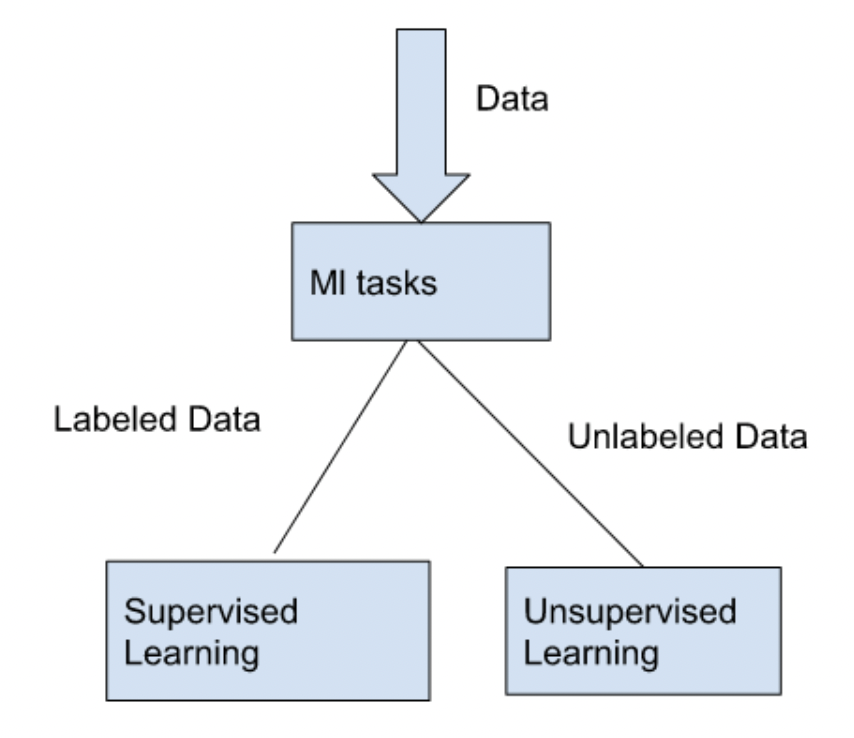
Types of learning in machine learning
Supervised learning
In this approach, we have labeled data, which means each piece of data comes with a special tag or label.
Supervised learning revolves around the use of labeled data, where each data point is associated with a known label or outcome. By leveraging these labels, the model learns to make accurate predictions or classifications on unseen data.
A classic example of supervised learning is an email spam detection model. Here, the model is trained on a dataset where each email is labeled as either "spam" or "not spam".
Another instance of supervised learning is a handwriting recognition model. By providing the model with a dataset of handwritten digits along with their corresponding labels, the model can learn the patterns and variations associated with each digit.
Categorical and continuous labels
Categorical labels are used when the target variable falls into a finite number of distinct categories or classes. These labels are also known as nominal or discrete labels.
A categorical label has a discrete set of values. Discrete is a term taken from statistics, referring to outcomes that can only take on a finite number of values, like days of the week. It is like having a limited number of options to choose from.
Continuous labels, also known as numerical labels, are used when the target variable represents a continuous or real-valued quantity. These labels can take on any numeric value within a certain range.
This means that a continuous label does not have a discrete set of values. There can be an unlimited number of possibilities. Think of it like a sliding scale instead of strict categories.
It is important to note that the type of label determines the type of machine learning problem with which you are dealing.
Categorical labels are associated with classification problems, where the goal is to assign a category or class to a given input.
Continuous labels are associated with regression problems, where the goal is to predict a continuous value.
But there are also hybrid problems that involve both categorical and continuous labels, such as multi-label classification or multi-output regression.
Supervised Learning Algorithms
Here are some impressive, supervised learning techniques you should know:
Linear regression
Linear regression is a fundamental technique in machine learning used to model the relationship between a dependent variable and one or more independent variables. It aims to find the best-fitting straight line that represents the linear relationship between the variables.
Linear regression is used in many real-world situations. For example, predicting house prices based on factors like area, number of rooms, and location.
Logistic regression
Logistic regression is employed when the target variable is binary or categorical. It predicts the probability of an instance belonging to a particular class. It is commonly used for tasks such as sentiment analysis or spam detection.
Instead of a straight line like in linear regression, logistic regression uses a special curve called the sigmoid or logistic function. This curve ranges between 0 and 1 and has a characteristic S-shaped form. It maps any input value to a probability value between 0 and 1.
Decision trees
Decision trees are graphical structures that help make decisions or predictions based on a set of conditions. They split the data into branches, where each branch represents a decision or outcome. Decision trees are widely used for classification tasks and can manage both categorical and continuous data.
The decision tree starts with a single node, called the root node, representing the entire dataset. Each internal node of the tree represents a decision based on a specific feature, and each branch represents the possible outcomes of that decision. The leaves of the tree represent the final predictions or outcomes.
Unsupervised learning: Extracting hidden patterns from unlabeled data
Unsupervised learning deals with unlabeled data, where no pre-existing labels or outcomes are provided. In this approach, the goal is to uncover hidden patterns or structures inherent in the data itself.
For example, clustering is a popular unsupervised learning technique used to identify natural groupings within the data.
By applying clustering algorithms to this data, you can identify distinct customer segments based on their similarities. This information can then be used to tailor marketing strategies or personalize recommendations for each segment.
Another compelling application of unsupervised learning is anomaly detection. In cybersecurity, unsupervised algorithms can analyze network traffic patterns that deviate from the norm. By detecting anomalies, potential security breaches or cyberattacks can be preemptively addressed.
Unsupervised learning algorithms
Unsupervised learning algorithms can be classified into two types of problems:
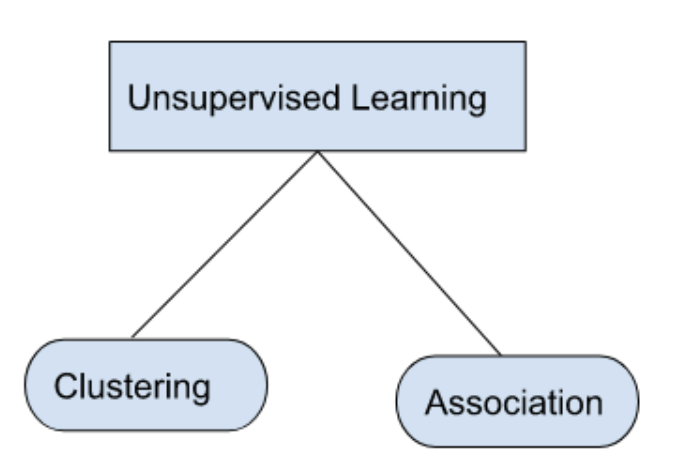
Types of unsupervised learning algorithms: clustering and association
Clustering
One unsupervised learning technique is clustering. Clustering is like a superpower that helps us determine if there are any naturally occurring groupings in the data. It is like finding friends who have similar interests without even knowing their names.
With clustering, you can group similar data points together and uncover meaningful patterns or structures in the data.
There are various clustering algorithms available, such as k-means, hierarchical clustering, and DBSCAN. These algorithms differ in their approaches, but the general idea is to measure the distance or similarity between data points and assign them to clusters. The number of clusters can be predefined (k-means) or determined automatically (hierarchical clustering).
Clustering has numerous applications, including customer segmentation, image recognition, document clustering, anomaly detection, and recommendation systems.
Association
Association is another technique in unsupervised learning that focuses on discovering interesting relationships or associations among different items or variables in a dataset. It aims to identify patterns that frequently appear together in the data.
The most well-known algorithm for association rule mining is Apriori. Given a dataset of transactions, Apriori finds sets of items that occur together frequently and derives association rules from them.
An association rule consists of an antecedent (or left-hand side) and a consequent (or right-hand side), indicating the presence of certain items implying the presence of other items.
For example, in a market basket analysis, association rules can be derived to identify items that are often bought together. These rules can help in making recommendations, optimizing store layouts, or understanding customer behavior.
Both clustering and association are unsupervised learning techniques that help to explore and analyze data without relying on predefined labels or classes. They play crucial roles in pattern discovery, data exploration, and gaining insights from unlabeled datasets.
Conclusion
Supervised and unsupervised learning represent two distinct approaches in the field of machine learning, with the presence or absence of labeling being a defining factor.
Supervised learning harnesses the power of labeled data to train models that can make accurate predictions or classifications.
In contrast, unsupervised learning focuses on uncovering hidden patterns and structures within unlabeled data, using techniques like clustering or anomaly detection.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

