
For decades Wall Street has used every source of data it can get its hands on to make predictions to guide stock market purchases. In the beginning, it was as simple as reading newspapers and ticker tape.
Although these companies don’t usually share their secrets, we know it has evolved to complex hand-written algorithms, machine learning, and, certainly now, artificial intelligence. However, it occurs to me that with the success of generative AI like ChatGPT, is there a new approach? I would love to know if this has already been tried and what the results were. For what it’s worth, here are my thoughts.
What if you could use generative AI to project the performance of various industries and businesses? What if we could look at the business performance over time as a novel being written by generative AI? At this point, we are not likely to affect pico-second stock purchase decisions due to model performance but we should be able to come up with some interesting short-term predictions.
Imagine predicting J.R.R. Tolkien‘s The Hobbit. If the beginning is Bilbo getting visited by Gandalf and the end is the predicted destruction of the ring, there are thousands of events (data points) that converge between those two points in time. But many of those data points could have been predicted if you knew what happened before the story began.
Isn’t the detail why we love the story so much? As the story unfolds, we learned this history — these data points. We learned how the ring was created. We learned of the history of Erebor, Smaug, and The Lonely Mountain. We learned of what happened to the kings who originally had the rings. We learned about Gollum and how he got the ring to rule them all and how it changed him.
If we knew all of this history before the story began, would we have been able to predict more of what was going to happen? Well, current experiences with generative AI (i.e. ChatGPT) shows that we would. Although some details would have been different, I think the story would have been very similar.
So what does this have to do with predicting a business’ performance? Well, if we look at stocks as a result of history past and present, we can see it as a math-dense novel hidden in massive amounts of text.
Predicting The Hobbit’s journey
So how would this work in The Shire? First, let’s create a simple linear graph of a small list of the events that occur in the journey from The Shire and back.
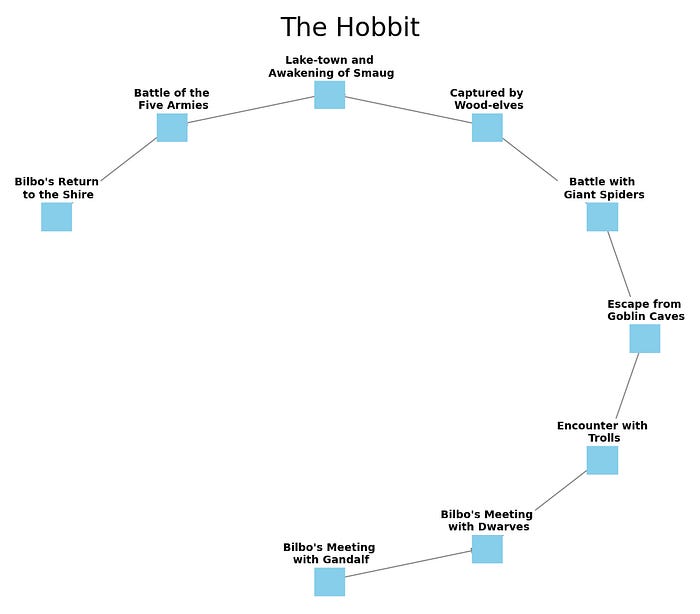
In the graph, we can see a representation of some different points in the story (a.k.a. history) that led up to the destruction of the ring and the return home. What this doesn’t show is all of the things that happened that led up to the beginning of the story. We learn these things as the story progresses and they are critical to the events and why they happen. So let’s add some history and the graph.
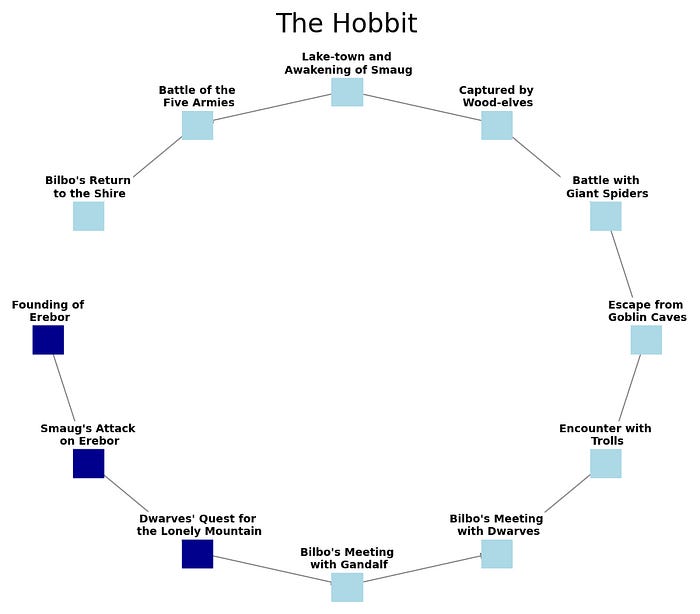
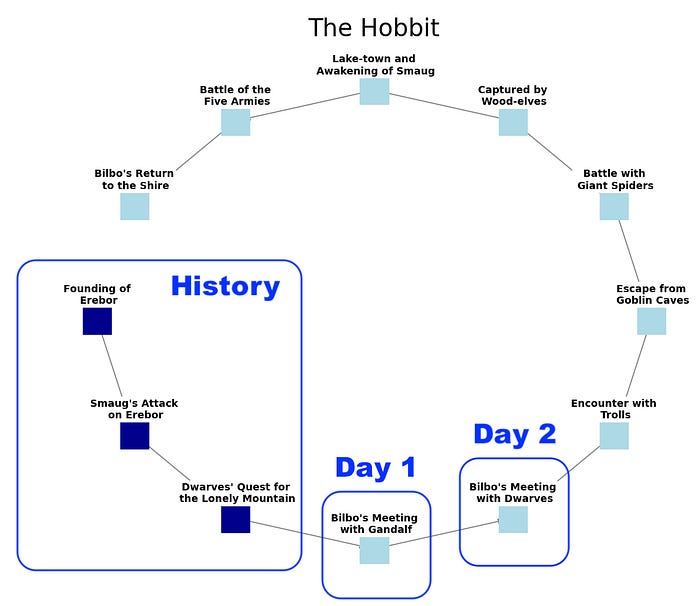
Of course, there is so much more detail in this novel. But you get the idea. If we knew enough details about the history leading up to the beginning of the novel before we started reading it, we could predict many of the events like the trek to Mordor. We might predict what events happened each day after leaving The Shire.
Moving into the real world
Now, let’s bring this story into the real world. If the end of our story is predicting the value of a company or stock, then everything leading up to it is real-life history, like the fictitious history in our novel, describing how the company got there.
NOTE: For those not familiar, completion task models take the start of a story like “Once upon a time” as input and then start generating a story from there. You can give it as much input as you want to get it started but it will take it from there.
NOTE: For those not familiar, completion task models take the start of a story like “Once upon a time” as input and then start generating a story from there. You can give it as much input as you want to get it started but it will take it from there.
So, from a technical, generative AI standpoint, if you took an LLM and did the following:
- Fine-tuned it for a completion task.
- Fine-tuned it on all of the history of Middle Earth (the world of The Hobbit).
- Started it with the prompt:
“In a hole in the ground there lived a hobbit. Not a nasty, dirty, wet hole, filled with the ends of worms and an oozy smell, nor yet a dry, bare, sandy hole with nothing in it to sit down on or to eat: it was a hobbit-hole, and that means comfort.”
You might end up with a story very similar to the one we all know and love.

So what might happen if we do something similar to this with real-world history? You might ask, isn’t that what we already have with GPT4? Well GPT4 is really close to that. That’s why it does such a great job with so many things. But, there are a few differences:
- It does not have the most recent information. (It was trained with data up through 2020.)
- It is trained on non-factual information from many sources. (Social media, novels, jokes, etc.)
- When it doesn’t have information, it makes stuff up. (Termed in the industry as “hallucinating”.
Therefore, we need to fine-tune it, place some guardrails on it, and give it a steady stream of new content.
For us, history will take the form of millions of data points representing:
- News stories on the company and its impact on sales, stock price, etc.
- News stories on the company’s industry and its impact on sales, stock price, etc.
- Stock performance relative to news stories.
- etc….
Remember that the diagram for The Hobbit is just a simplification of the history of Middle Earth. A “real” diagram would not be linear at all. It would quickly become unreadable. So when we expand this to the real world, we won’t try to extend that visualization. I think we would lose our minds.
Creating history for our story
So how would we go about this? Well, we laid out the steps above.
- First, we need an LLM that is fine-tuned for completion. (Think completing our story.) There are a few out there both open-source and commercial.
- Fine-tune it on the history of world finance and business. (Ok, this is big.)
- Set some guardrails.
The first step is easy. As I mentioned, you can find a lot of them to use. You can create your own if you like. If your use case is as big as predicting stock values, the financial cost is worth it. However, you will need to decide if spending time doing this is worth it. The months of delay in getting your product up and running could mean your competitors beat you to it. And, you can always swap in your private LLM later.
Let’s start with the article:
“Volkswagen brand will only produce electric cars in Europe from 2033 -brand chief.” link
Today we might have used a sentiment analysis of this article as a feature (input) to a standard ML algorithm like XGBoost, but it would be better to take the whole article and take advantage of all its information like:
“Schaefer said in the coming decade the VW brand would narrow down the number of models on offer and raise the profit margin for all volume brands — Volkswagen, SEAT and Skoda, and commercial vehicles — to 8% by 2025.”
Using articles like this in fine-tuning adds to our “history” and even gives us a glimpse of the future. This will help direct the Generative IA in its predictions so that our generated story is more accurate.
This news was announced on Oct. 26, 2022, so we could see only the beginnings of how this will affect VW’s history. But with this approach, including articles on all industries and companies, we are building a picture of the world as it changes. It’s not just The Shire but the whole of Middle Earth.
And, this is the way the world works, right? Looking at one industry in isolation is too limited. Issues like the price of fuel, global supply issues, war, rare minerals, new inventions/technology, etc. Even AI is affecting EV adoption. (Who might have seen that 10 years ago.)
Generating training data
Finding, curating, and cleaning reliable training data is always the biggest part of creating a good AI model. It is also critical that the data be clean and accurate. However, there are a few ways to use AI to actually create the training data for us.
One way is to use Generative Adversarial Networks (GANs) to help improve the training. In short, a GAN involves a second model that sort of “grades” our model during training. It would work something like this:
- The 2nd model generates new text (a news article) that may or may not reflect a past outcome.
- The generated (fake) article is sent to the first model for a prediction.
- The 2nd model already knows what the 1st model should predict so if the prediction is wrong, it is used to train the model for the next time.
The idea is that you have 2 models fighting with each other in order to help them improve. This greatly reduces the amount of training data you will need to tag manually.
Another way to do this is to use AI to summarize existing articles so that we can remove unnecessary noise. We could even decide to reduce articles to certain formats like CSV files or bulleted lists by topic. AI is pretty good at doing this so we may be able to generate a lot of data using AI itself that way too.
Let me know your thoughts in the comments below. Do you think this idea will work?


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

