
As semiconductor technologies scale, we are quickly approaching a stage where we can pack enough computational power into AI-processing silicon chips, such that they could soon rival the processing capability of the human brain. This would bring about a fundamental change in the role of computers in our societies.
However, to make human brain-level computing power pervasive, whether it is in the data center or at the edge, we still have one important challenge to overcome: to make such processors energy efficient.
In this article, I’ll take us back in history to examine how researchers drew inspiration from studies of neuronal substrates of intelligence in the biological brain, and derived computational models of such intelligence, as well as much more energy-efficient methods for information processing.
I’ll examine the role of noise, quantization, and dynamic range in processing elements, as well as the costs of moving data across wires, and discuss methods to optimize them to achieve not only energy efficiency, but also a better, and perhaps more biologically plausible way to generalize from data in performing machine learning.
Human brain processing power: The next generation of AI computing?
The topic of my article is to scale data center processors to the level of human brain processing power to be able to power the next generation of AI computing.
When I talk about human brain processing power, there are two meanings to it. One is in terms of the processing power - it can be scaled to the level of one exaflop. The other aspect of this is a project called the Human Brain Project, an EU-sponsored project where they will start to provide processing power in the data center on an exaflop scale, which can be used to simulate AI in neuroscience, and also brain-related medicine.
Performance plateau: slow wires
To start my article, I would like to point out the main barrier to us scaling computing power to a very high level (as you may know from your experiences with your own PCs) is that in the last 10 years or so, the processing power of our computers hasn’t really increased that much.
Even though we have continuously scaled in terms of semiconductor technology, the fundamental problem is the so-called wire delay problem.
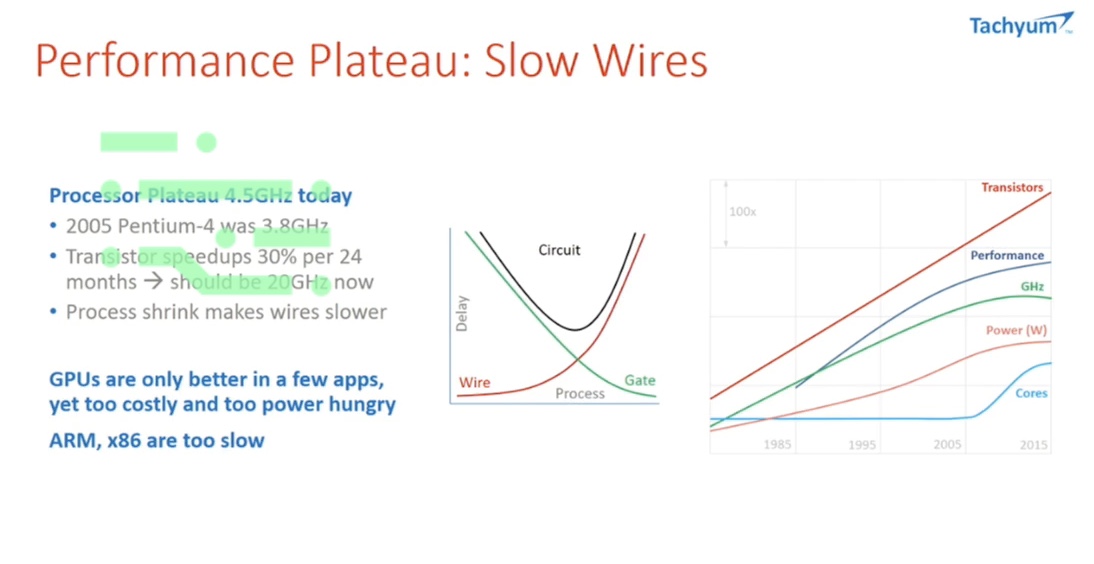
Essentially, as we have smaller and faster transistors, we can pack a lot of computing power into a chip, but then the wire becomes slower.
So, we cannot feed enough data to those processing units and end up having this plateau in terms of the computing capability of our chips.
What would be the solution?
Solution: energy-efficient AI
The solution we are proposing is a fundamentally different architecture, which will rely on much shorter wires in transmitting data between processing units, whilst adding the high-performance interface so that such computing power can scale.
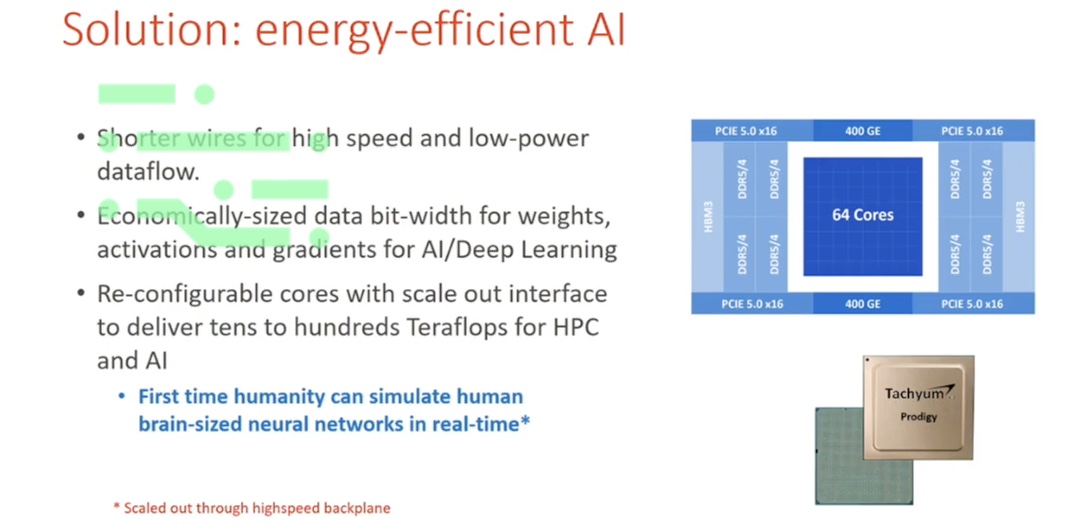
One of the challenges of dealing with this kind of architecture is: what kind of data are you flowing between different processing units?
Here, we're going to look into data quantization for AI, but also look at the dynamic range, and the stochastic properties of the data as they flow between the processing units.
We would argue that with these kinds of technology, we can eventually build a reconfigurable processor, that can produce up to one petaflop of processing power per chip.
You can then scale that to 1000s of chips using high-speed interfaces with error correction coding technology, and be able to reach exaflops of processing power.
Inspiration
Before diving in, the inspiration behind some of the work we're doing should be considered. Our understanding of AI benefited a lot from the study of biology, dating back to the 90s.
For example, when scientists studied neural networks, they started with giant squid, because they have a neuron so large you can actually poke an electrode into it and record activity.
Neuronal substrate of learning - AI benefited from study of biology
One of the studies conducted in the 90s was on insects with spiking neurons. These ideas helped to contribute to today's new thinking in computing architecture.

The image above shows a study conducted on stick insects. Stick insects were chosen due to their large neural system. Unlike a brain, their system consists of neurons running along the body that we call 'neural ganglia'.
By probing electrodes into the insects while they're running on the treadmill, their neuronal activities can be recorded. From this, we can understand how sensory information is synthesized into meaningful actions, in this instance making the insects traverse across rough terrain.
Neuromorphic insect-like robot real-time learning - circa 1996
Following this, a robot based on the architecture of the neuron was built, and we simulated the spiking neuron with a digital signal processor, to understand the neuronal processing of information for learning and information processing.
The below image depicts a robot powered by a TI DSP, doing what's called 'self-supervised learning', where it's attempting to build a map between actuators and a sensor, to adjust the flexibility and the compliance of the drawings to achieve so-called 'substrate finding' behavior.

Similar to the insects as they traversed across the rough terrain, this robot is trying to constantly find a foothold. For example, if a terrain were to be spanned by tree branches, the robot will learn and build reflexes so to always find a foothold as it progresses along.
This work was sponsored by DARPA and the Office of Naval Research, and TI contributed their early generation of DSP processor to simulate the spiking neurons.
Myself and my partner built this system and we actually won awards, sponsored by EE Times. Shown in bottom right of the image is the IC pioneer Jack Kilby, who was credited for inventing integrated circuits.
Let's fast forward to 2019...
Weight, activation, and gradient quantization in Tensorflow
There are plenty of interesting ideas we can learn from the biological neural systems, not only in terms of how to process information and generate meaningful behaviors, but also how to do so in an energy-efficient way.
What we find is that the real neural system is actually very economical when it comes to the dynamic range of the different elements, be it the synapses, neurons, or axons.
Additionally, the right amount of noise, or stochastic property is factored in, which will actually help with dealing with transmitting information with very limited resolution.
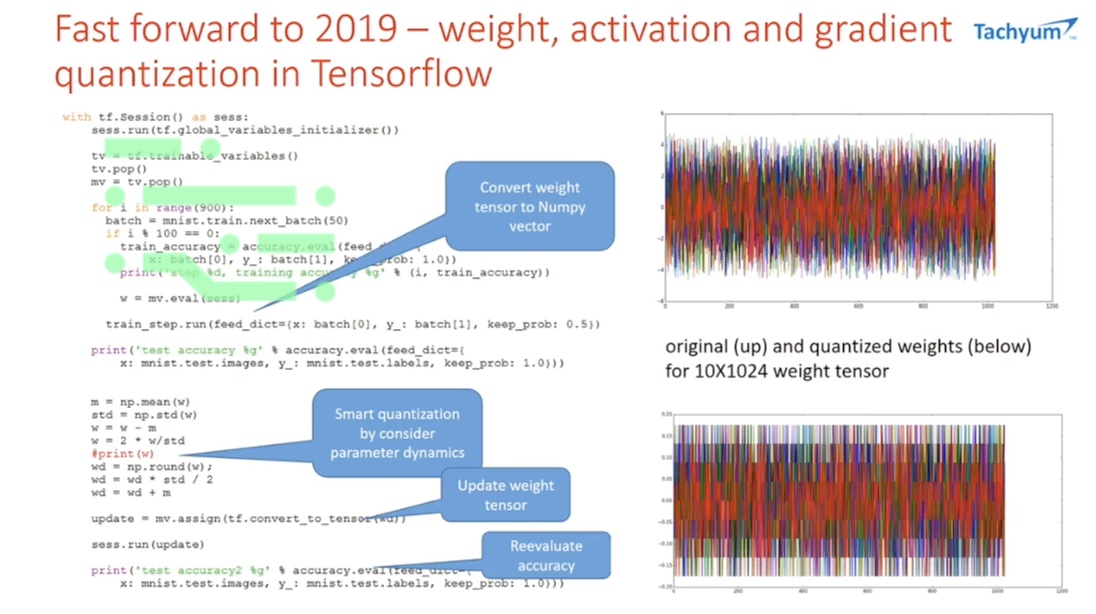
By taking this inspiration, we can cross-validate in Tensorflow. So from this we can go into Tensorflow and play around with it. Due to this being an earlier version of Tensorflow, we had to pull the data out and feed it into NumPy before adding noise and quantization, and adjusting the dynamic range of the processing elements, in order to learn the results.
Cifar-10 with Vgg_19 - go deep with low bit-width weight, activation, and gradient data
From this we can get a pretty good performance with convolutional neural networks with different levels of quantization, noise, and even nonlinear encoding of states.

Cifar-10 on VGG_19 - effect on quantization - consistent or better IEEE floating point
The below image shows that by using different levels of quantization for weights, activation and gradients, we can get a fairly good performance, up to a very low level of bit-widths.
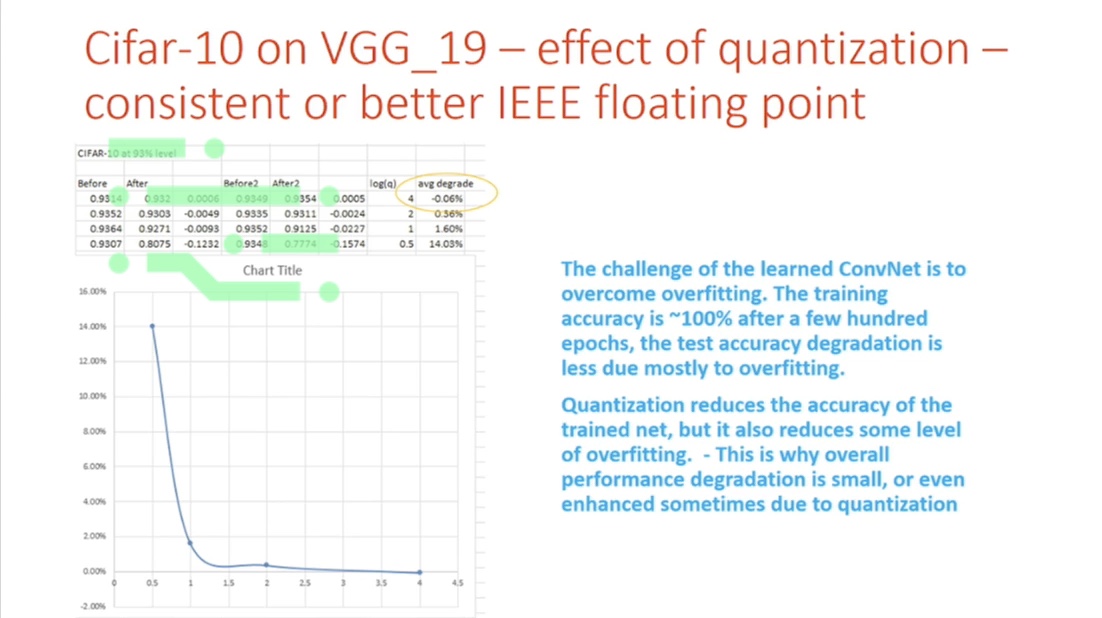
Surprisingly enough, by adding noise, quantization, and some nonlinearity in the processing, can actually improve the performance in some cases, because it has the capability to overcome overfitting, and these results are encouraging.
Weights quantization - linear vs nonlinear
The goal here is to build processing units that have a limited number of discrete states, and are adapted to the dynamic range of the signal it needs to carry. These can even be nonlinear, so to achieve greater energy efficiency.
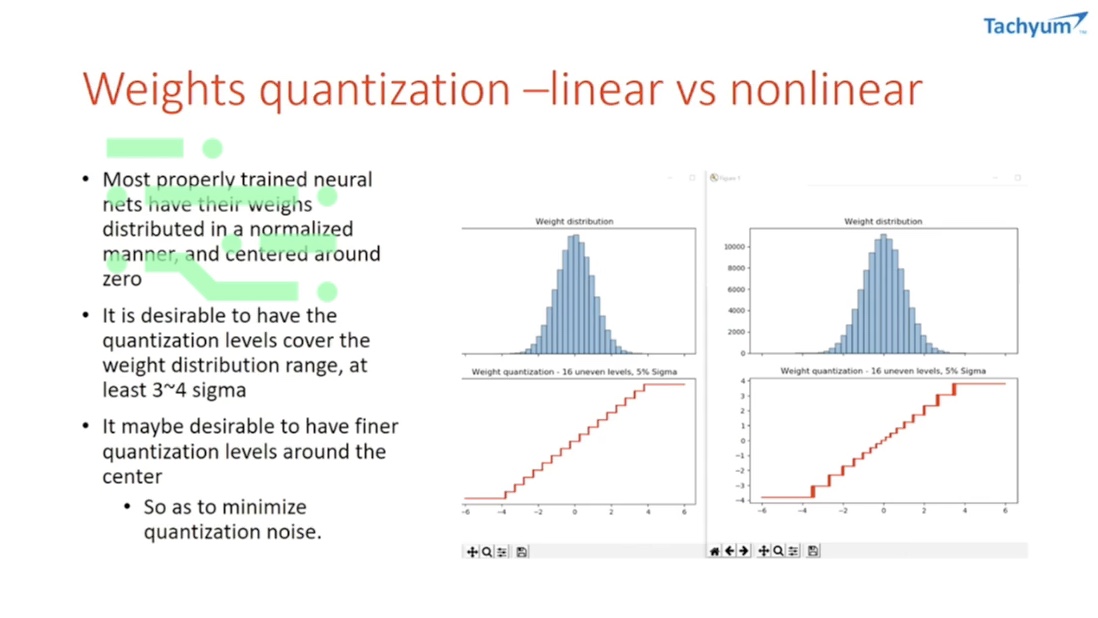
Some typical quantization codes
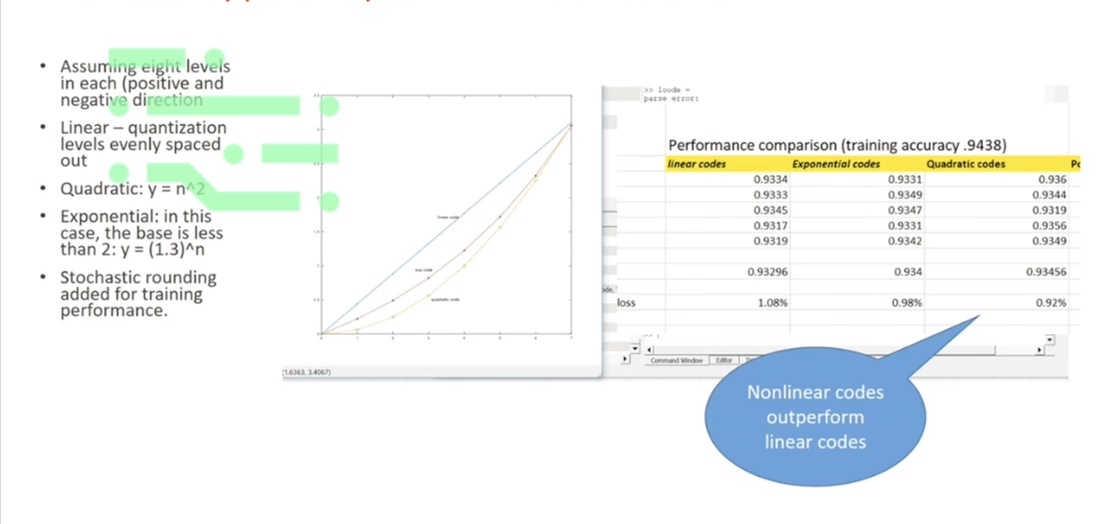
Different types of nonlinear codes were tried and it was found that certain types of nonlinear codes gave us the best representation of the neuronal data.
Low bit-width-data operation in SIMD vector processor
From this we can glean an interesting implication, that being that with certain nonlinear codes, we can suddenly perform multiplication much cheaper and faster with transistors.
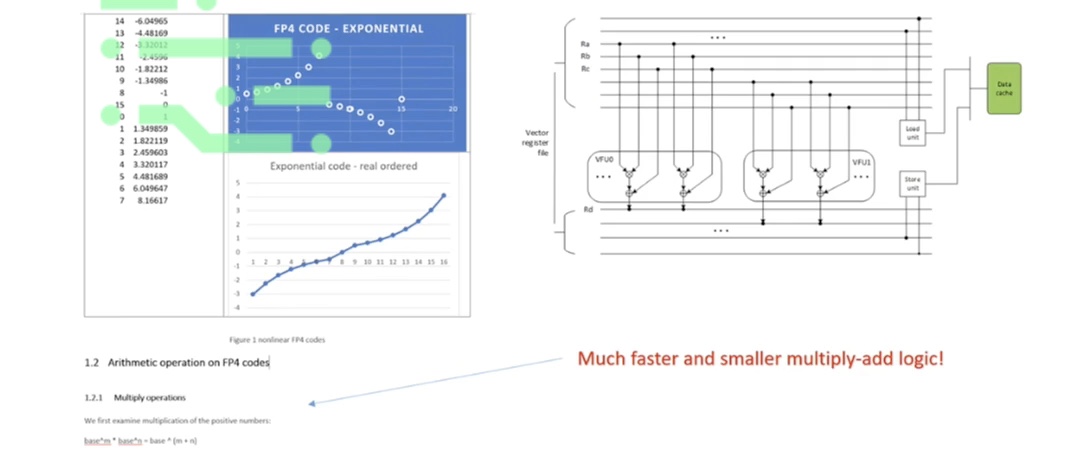
For example, if we build a nonlinear code that's exponential, then suddenly multiply becomes adds, then we perform it much faster and achieve it with fewer switches between gates.
Tensor data amortization network
This architecture can then be coupled with a data distribution network to maximize the data amortization. This can aid us in achieving much more energy-efficient processing, which is very easy to program in this type of processor.
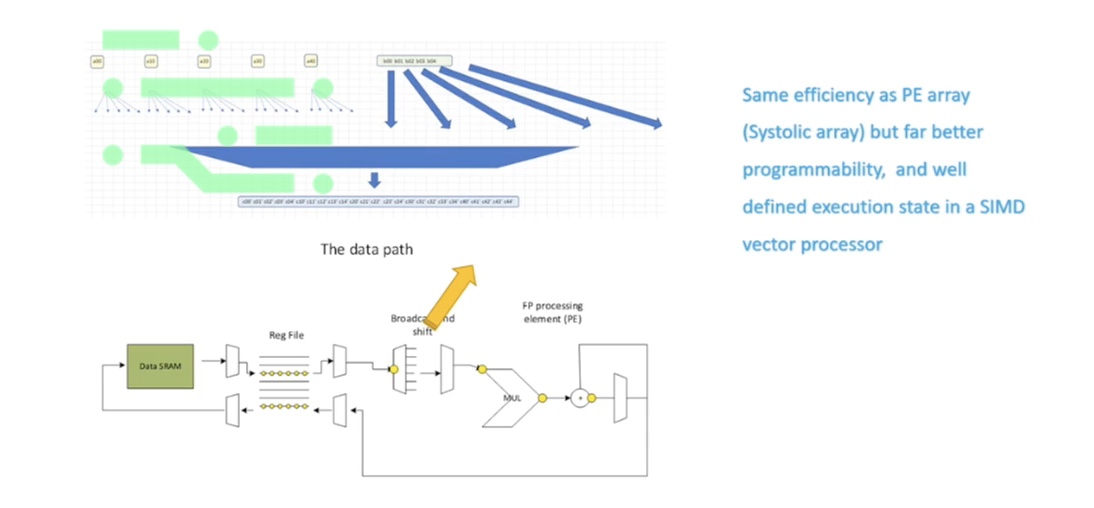
With this approach, we compared the architecture to more modern architectures, such as systolic array, and found our approach actually had the advantage of a very conventional programming model and a well-defined execution state.
As you know, when writing programs, sometimes you want to set up breakpoints or be able to freeze the code and then look at all the variables. With a lot of modern architectures, this is no longer possible, so when building and inventing applications using this, it will be very hard to debug.
We try not to take that away from you.
We are building a processor that has a relatively simple programming model and a well-defined state, but will give you the efficiency and performance of more exotic architectures.
Putting it together: Prodigy universal processor / AI chip
This is behind what we call a 'prodigy processor'.
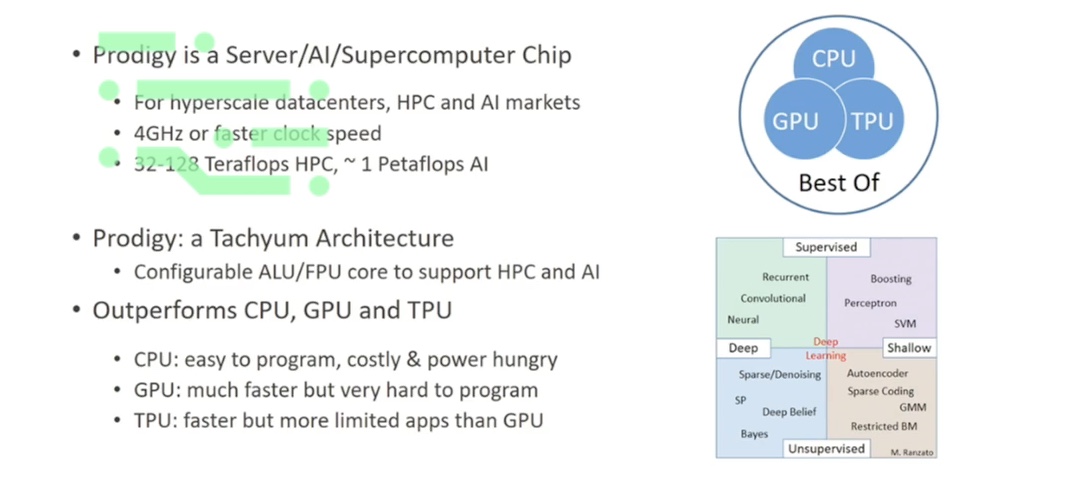
This is a processor that's been designed and built by Tachyum and it will be built on the semi nanometre TSMC FinFET process, and it will be running at four gigahertz or higher.
Prodigy chip w/ interface for hyperscaling
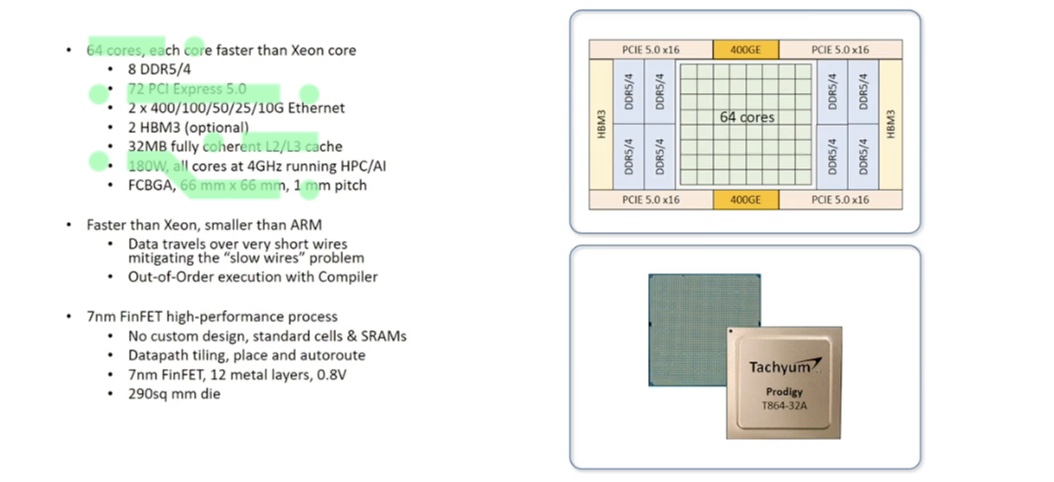
As mentioned, this is a processor that can be scaled out, so it will have interfaces that can give you a 400 gigabit per second backplane that will have two of those interfaces. We can scale multiple of those processors into large clusters of compute, and also have 72 lanes of PCIE 5.0 interface and will have eight DDR controllers or HBM memory interface.
With this kind of power in terms of the interface, we can easily have a multitude of those processors built-in to give you multiple petaflops of processing with a very energy-efficient footprint.
It's important to note that if you're going to have a cluster with hundreds of processors running hundreds of hours with petaflops of memory, the chances are large that one of the memories is going to burn out during the process.
Hence, we have built powerful ECC technology into this chip, so that even if one lane of DRAM is dead it will continue to run, it will not crash and your data will not be lost.
This is one of the more challenging aspect of hyperscale data center chips: how long you can run before crashing? Even if a processing core crashes, the ECC will recover the data.
The founder of this company actually is the founder of Sandforce, the company that builds the flash controllers for the PCIE SSDs, and many of us are coming from previous data center backgrounds where a hyperscale data center processor with high reliability is of a great importance to us.
DRAM controllers, I/O and Mesh for Prodigy chip
An important aspect to mention is easy programmability, because our customers are programmers, and we want them to be able to innovate.
This chip is built with a 64 core processor with a fully coherent cache system, so that you can easily deploy your algorithm into multicores without worrying about the coherency of memory.
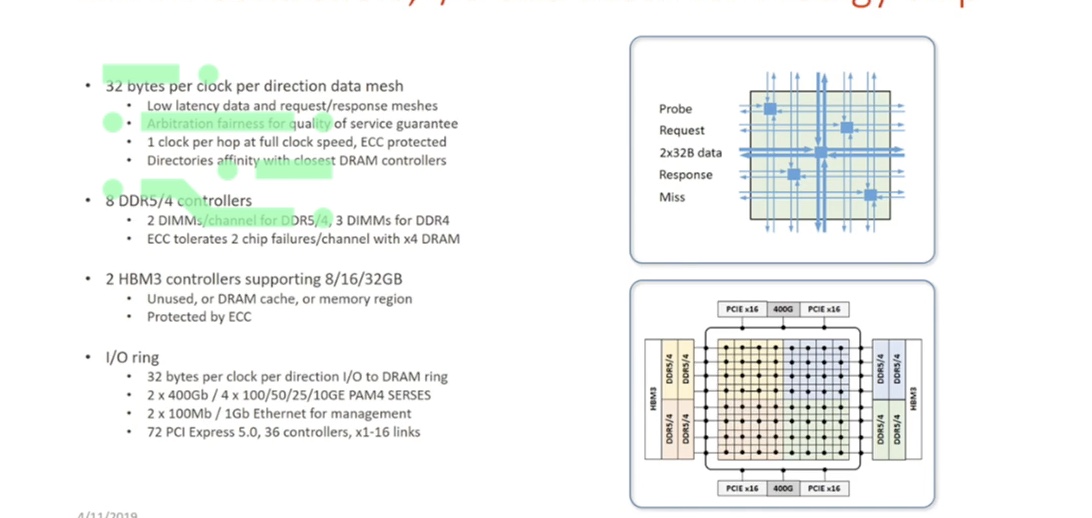
This is very important when innovating.
This process is not purely AI, but rather the mix of AI and high-performance computing. It's capable of also doing 64-bits double-precision IEEE standard floating points with a configuration switch, so you could build a highly proven simulation system and then run alongside AI to learn from the simulation.
Alternatively, you can run high-performance business-oriented computation during the day and run AI training at night.
This is the idea behind the Tachyum Prodigy processor.
Brain simulation in hyperscale data center
The picture below shows the founder of our company, Radoslav Danilak, and on his side is Steve Furber, the founder of ARM and also the original designer of the ARM processor.

He's currently heading up the European human brain project. We are working together to get this chip into data centers to satisfy these needs.
Currently, we already have a cluster using a process called SpiNNaker. These are ARM-based processors that simulate spiking neurons. We used half a million of these processors to simulate one exaflop of processing.
But with the Tachyon Prodigy processor, we can do it much more efficiently.
Additionally, we'll be using our partner’s PAM4 switch chips over copper, for lane to lane communication, and then we can use one or two fiber based switches to further aggregate.
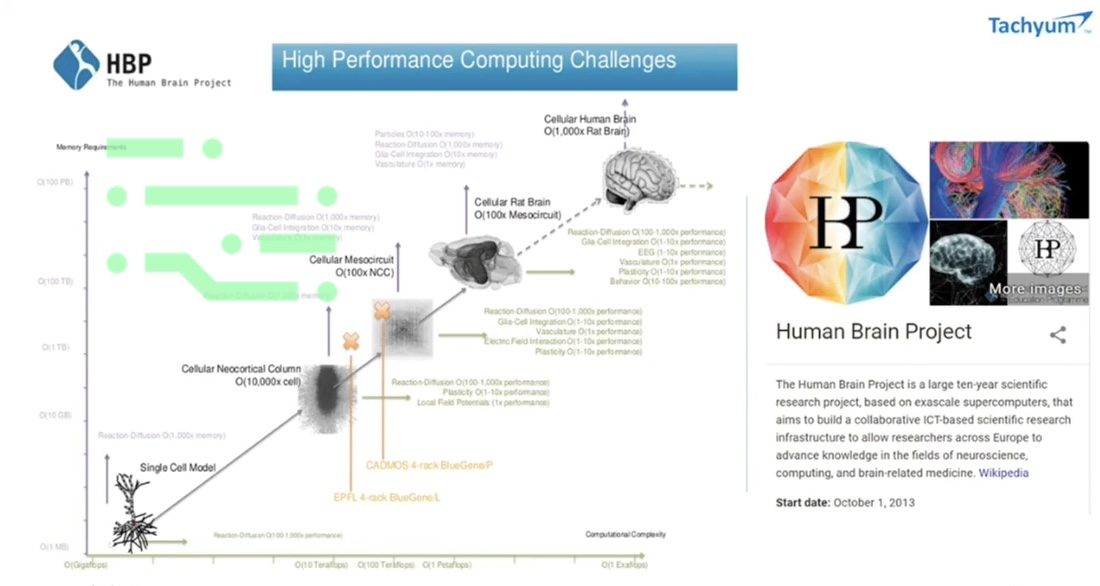
The idea of actually deploying enough processing power in a data center to amount to one exaflop of processing power that's accessible to anybody is significant, as there will be a lot of innovations that can be done with access to a large amounts of processing power and lots of memory with the kind of reliability that allows you to run hundreds of thousands of hours of compute, and find out what happens.
This is our vision, and we are currently working hard to make this a reality.
This project is supported by several entities including the European Union, and investors from both the United States and from Asia.


AI accelerator insider insider
Thank you for subscribing
Level up your ai accelerator insider career & network with ai accelerator insider experts.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn

